在当今数字媒体时代,声音特效的应用越来越广泛,无论是游戏开发、影视制作还是音频设计,独特的声音效果都能为作品增色不少。然而,传统的声音特效制作往往需要专业的设备和技术,对于普通用户来说门槛较高。随着人工智能技术的快速发展,AI声音特效生成器应运而生,它能够通过简单的文本描述,自动生成各种各样的声音效果,极大地降低了制作成本和难度。本篇博客将带你了解如何使用FlutterFlow和Replicate构建一个简单但功能强大的AI声音特效生成器。FlutterFlow是一个强大的低代码开发平台,可以帮助我们快速构建用户界面,而Replicate则是一个云平台,提供了各种各样的AI模型,包括声音生成模型。通过将两者结合,我们无需编写复杂的代码,即可创建一个AI声音特效生成器,让用户通过简单的文本描述和参数调整,就能生成自己想要的声音效果。这将极大地简化声音特效的制作流程,为内容创作者提供更多可能性。本文将详细介绍构建该生成器的步骤,并分享一些SEO技巧,帮助你更好地推广你的作品。无论你是开发者、设计师还是内容创作者,都可以从中受益。
关键要点
- 利用FlutterFlow构建用户友好的声音特效生成器界面。
- 使用Replicate提供的AI声音生成模型。
- 无需编写大量代码,即可实现AI声音特效生成。
- 通过文本描述和参数调整,生成定制化的声音效果。
- 学习如何集成FlutterFlow和Replicate。
- 掌握使用API调用AI模型的方法。
- 优化应用以获得更好的性能和用户体验。
- 声音特效生成器可以广泛应用于游戏开发、影视制作、音频设计等领域。
- 通过SEO优化,提升应用的曝光率和用户获取。
AI声音特效生成器:技术与应用
什么是AI声音特效生成器?
AI声音特效生成器是一种利用人工智能技术,尤其是深度学习模型,来自动生成各种声音效果的工具。传统的音频制作方法需要专业的录音设备、声音设计师以及复杂的后期处理过程,而AI声音特效生成器则通过算法模拟这些过程,大大降低了制作门槛和成本。用户只需要提供一些文本描述,例如“汽车引擎的轰鸣声”、“森林中的鸟鸣声”或“科幻武器的发射声”,AI就能根据这些描述生成相应的声音效果。
这种技术依赖于大量的音频数据和先进的机器学习算法。模型通过学习这些数据中的模式和规律,从而能够根据新的文本描述生成具有相似特征的声音。目前,常见的AI声音特效生成器使用循环神经网络(RNN)、变分自编码器(VAE)以及生成对抗网络(GAN)等模型。这些模型各有优缺点,适用于不同的应用场景。AI声音特效生成器正在改变音频制作的格局,为游戏开发者、影视制作人、音频设计师以及其他内容创作者提供了更便捷、高效的解决方案。通过使用这些工具,用户可以快速生成各种高质量的声音效果,从而提升作品的吸引力和表现力。
FlutterFlow:低代码开发的强大平台
FlutterFlow是一个基于Flutter框架的低代码开发平台,旨在帮助开发者和设计师快速构建高质量的移动应用。它提供了一个可视化的界面,用户可以通过拖拽组件、配置属性等方式,轻松构建用户界面,无需编写大量的代码。FlutterFlow还集成了Firebase等后端服务,方便用户进行数据存储、用户认证等操作。使用FlutterFlow构建应用具有以下优势:
- 快速开发:通过可视化界面和预置组件,大大缩短开发周期。
- 跨平台支持:基于Flutter框架,可以同时生成iOS和Android应用。
- 易于使用:无需深厚的编程知识,即可快速上手。
- 高度定制:可以自定义组件和代码,满足各种需求。
FlutterFlow非常适合构建各种类型的应用,包括电商应用、社交应用、内容管理系统以及本篇博客中介绍的AI声音特效生成器。它的易用性和灵活性,使得开发者可以将更多精力放在应用的功能和用户体验上,而不是繁琐的代码编写上。
Replicate:云端AI模型的中心
Replicate是一个云平台,旨在简化AI模型的部署和使用。它提供了一个统一的API接口,用户可以通过简单的HTTP请求,即可调用各种各样的AI模型,无需关心底层的硬件和软件环境。Replicate还支持Docker容器,方便开发者将自己的AI模型部署到平台上。Replicate的优势在于:
- 丰富的AI模型:平台集成了各种各样的AI模型,涵盖图像生成、文本生成、语音生成等领域。
- 易于使用:通过简单的API接口,即可调用AI模型。
- 云端部署:无需关心底层的硬件和软件环境,模型部署简单快捷。
- 可扩展性:平台可以根据需求自动扩展资源,满足各种规模的应用。
Replicate是连接AI模型与应用的桥梁,使得开发者可以更加便捷地利用AI技术,为自己的应用增加更多创新功能。在本篇博客中,我们将使用Replicate提供的声音生成模型,为我们的AI声音特效生成器提供核心功能。
使用FlutterFlow和Replicate构建AI声音特效生成器
项目设置与准备
在开始构建AI声音特效生成器之前,我们需要进行一些准备工作:
- 注册FlutterFlow账号:访问FlutterFlow官网,注册一个账号。
- 创建FlutterFlow项目:登录FlutterFlow后,点击“Create New”按钮,创建一个新的FlutterFlow项目。选择一个合适的模板,或者从头开始创建一个空白项目。
- 注册Replicate账号:访问Replicate官网,注册一个账号。
- 获取Replicate API Token:登录Replicate后,在Dashboard页面可以找到你的API Token,请妥善保管,后续调用API时需要使用。
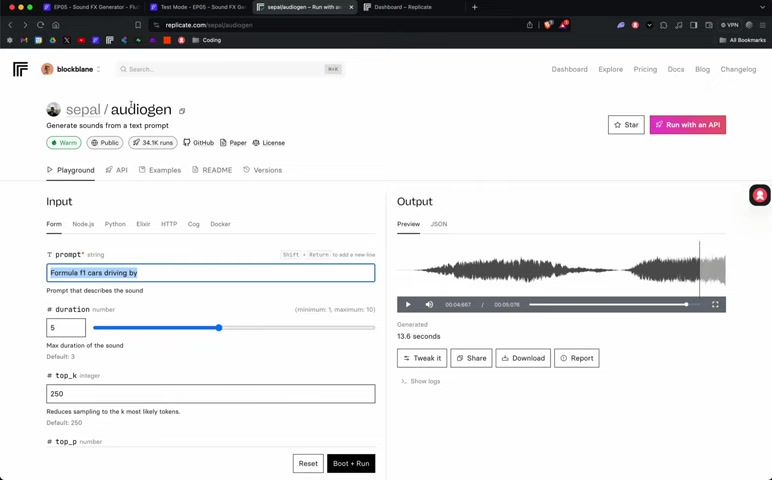
- 了解Sepal AudioGen模型:本教程中使用sepal/Audiogen模型,这是一款强大的AI模型,可以根据文本生成各种声音。
访问Replicate的sepal/audiogen模型页面,了解模型的输入参数和输出结果。记住,使用此模型需要API Token,因此,请按照上述流程获取属于你自己的token。准备工作完成后,我们就可以开始构建AI声音特效生成器了。
构建用户界面
在FlutterFlow中,我们可以通过拖拽组件的方式,快速构建用户界面。我们需要以下几个核心组件:
- TextField:用于用户输入文本描述,例如“汽车引擎的轰鸣声”。
- Slider:用于用户调整声音特效的参数,例如最大时长。
- Button:用于触发声音特效生成。
- Lottie Animation:用于在声音特效生成过程中显示加载动画,提升用户体验。
- Audio Player:用于播放生成的声音特效。


将这些组件拖拽到画布上,并进行适当的布局和样式调整,即可构建出一个用户友好的声音特效生成器界面。你可以根据自己的喜好和需求,自定义组件的样式和属性,例如颜色、字体、大小等。为了提高用户体验,我们可以为TextField组件添加提示文本(Hint Text),例如“请描述你想要的声音特效”。对于Slider组件,我们可以设置最小值、最大值和步长,以便用户进行精确的参数调整。对于Button组件,我们可以设置点击事件,触发声音特效生成。
集成Replicate API
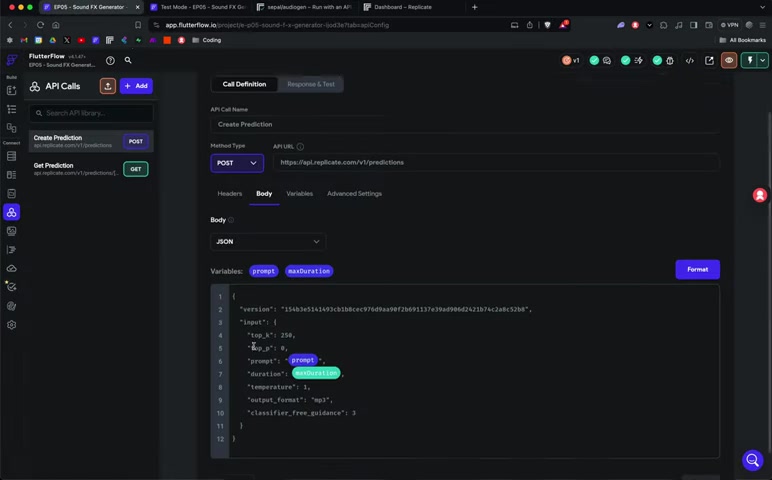
接下来,我们需要将Replicate API集成到FlutterFlow项目中。首先,在FlutterFlow中创建一个API Call,并进行如下配置:
- API Call Name:CreatePrediction
- API URL:
https://api.replicate.com/v1/predictions - Method Type:POST
- Headers:Authorization: Token YOUR_REPLICATE_API_TOKEN, Content-Type: application/json
将YOUR_REPLICATE_API_TOKEN替换为你自己的API Token。然后,在Body中添加以下JSON数据:
{
"version": "154b3e5141693cb1bcec97f2b691137e39d6986d2421b74c2c8e52b8",
"input": {
"prompt": "YOUR_PROMPT",
"duration": YOUR_DURATION
}
}将YOUR_PROMPT和YOUR_DURATION替换为变量,分别对应用户输入的文本描述和声音特效的时长。创建API Call后,我们需要测试一下是否能够成功调用Replicate API。在FlutterFlow中点击“Test API Call”按钮,输入测试数据,例如“汽车引擎的轰鸣声”和“5”,如果返回状态码为201,则表示API调用成功。
接下来,我们需要创建一个GetPrediction API Call,用于获取声音特效的生成结果。进行如下配置:
- API Call Name:GetPrediction
- API URL:
https://api.replicate.com/v1/predictions/{id} - Method Type:GET
- Headers:Authorization: Token YOUR_REPLICATE_API_TOKEN, Content-Type: application/json
将{id}替换为变量,用于传递CreatePrediction API Call返回的ID。同样,测试GetPrediction API Call,如果返回状态码为200,则表示API调用成功。
实现生成和播放声音特效的逻辑
在FlutterFlow中,我们需要编写一些逻辑代码,实现生成和播放声音特效的功能:
- Generate Sound FX按钮的点击事件:
- 更新页面状态:设置predictionLoading为true,显示加载动画。
- 调用CreatePrediction API Call:将用户输入的文本描述和声音特效时长传递给API,生成声音特效。
- 启动定时器:每隔5秒调用一次GetPrediction API Call,检查声音特效是否生成完成。
- GetPrediction API Call的调用逻辑:
- 判断声音特效是否生成完成:检查API返回的状态码,如果为200,则表示生成完成。
- 更新页面状态:设置predictionLoading为false,隐藏加载动画。
- 将API返回的声音文件URL传递给Audio Player组件,用于播放声音特效。
- 停止定时器:停止调用GetPrediction API Call。
- Audio Player组件的播放逻辑:将声音文件URL传递给Audio Player组件,即可播放声音特效。
通过以上逻辑,我们可以实现一个完整的AI声音特效生成器。用户在输入文本描述和参数后,点击“Generate Sound FX”按钮,即可在云端生成声音特效,并在应用中进行播放。
AI声音特效生成器的使用方法
创建Replicate账户并获取API密钥
首先,访问Replicate官网并创建一个账户。注册完成后,在您的账户控制面板中找到API密钥,并妥善保管。该密钥将用于在FlutterFlow应用中验证您的身份,并允许您访问Replicate的AI模型。
创建Replicate API在FlutterFlow中配置API调用
- 创建POST API调用:在FlutterFlow中,创建一个新的API调用,并将其设置为POST方法。将API端点设置为Replicate的预测端点:
https://api.replicate.com/v1/predictions。设置请求头:添加必要的请求头,包括您的Replicate API密钥:Authorization: Token YOUR_REPLICATE_API_TOKEN,Content-Type: application/json。定义请求体:构建JSON请求体,指定要使用的Replicate模型版本和输入参数(例如,提示文本和持续时间)。 - 创建GET API调用:创建另一个API调用来检索预测结果,并将其设置为GET方法。使用带有预测ID的Replicate端点:
https://api.replicate.com/v1/predictions/{id}。
将用户界面元素连接到API调用
- 绑定提示文本:将文本字段小部件绑定到提示参数。这将允许用户输入他们想要的声音特效的描述。
- 配置最大持续时间滑块:将滑块小部件连接到持续时间参数。用户可以使用此滑块来指定声音特效的最大持续时间。
- 设置“生成声音特效”按钮:配置按钮以触发POST API调用。配置API调用以使用来自文本字段和滑块小部件的提示文本和持续时间。
- 定期检查预测状态:创建定期操作以检查预测的状态。这将确保您的应用程序在预测准备好时立即显示生成的音频。
Replicate模型定价
模型运行成本
Replicate上运行模型的成本取决于模型本身及其计算需求。Sepal AudioGen模型当前的运行成本约为每次运行0.035美元。Replicate为免费使用提供了一些信用额度,之后您需要添加信用卡才能继续使用。成本计算基于GPU的使用量,因此更复杂的模型或更长的持续时间将导致更高的成本。请查看Replicate上的定价页面,了解最新信息。
AI声音特效生成器的核心功能
AI驱动的声音生成
核心功能当然是AI驱动的声音生成。用户可以使用文字提示创建各种各样的声音特效。用户可以指定持续时间等参数来控制声音特效。强大的后端调用使结果精准。
可视化FlutterFlow界面
FlutterFlow的可视化拖放界面简化了应用的设计和开发过程。无需编写大量代码即可创建自定义界面。集成了Replicate API,从而可以通过API调用轻松使用各种AI模型。
易于部署和分享
Replicate提供的云端部署选项使部署和共享你的声音特效生成器变得简单。快速开发和模型迭代也十分便利。
AI声音特效生成器的应用场景
游戏开发
AI声音特效生成器可以用于快速生成游戏中的各种声音效果,例如脚步声、武器声、环境声等。节省游戏开发时间和成本,允许快速试验不同的声音设计。
影视制作
在影视制作中,AI声音特效生成器可以用于生成各种环境音效、特效音效等,丰富影片的听觉体验,并且可以通过更便捷的方式进行声音后期的创作。
音频设计
音频设计师可以使用AI声音特效生成器来快速生成各种声音素材,用于音乐创作、广告制作等。可以作为创意工具,探索新的声音组合和可能性。
其他领域
AI声音特效生成器还可以应用于虚拟现实、增强现实、教育等领域,为各种内容创作提供更多可能性。简化声音后期处理,降低非专业人士进入音频创作领域的门槛。
常见问题解答
构建此AI声音特效生成器需要什么技能?
主要需要对FlutterFlow平台和API调用有一定的了解。熟悉Replicate平台及模型使用会有所帮助,但不需要深入的AI背景知识。
我可以使用其他AI声音生成模型吗?
当然可以。Replicate平台上有许多声音生成模型可供选择。您可以修改API调用以使用其他模型,并调整FlutterFlow应用以匹配新模型的输入和输出。
此AI声音特效生成器是否可以商用?
这取决于您使用的Replicate模型及其许可条款。请仔细阅读模型许可,确保您的使用方式符合规定。
相关问题拓展
如何优化AI声音特效生成器的性能?
AI声音特效生成器的性能优化是一个涉及多方面的问题,包括前端界面优化、API调用优化以及模型优化等。针对不同的环节,可以采取不同的策略。
- 前端界面优化:减少不必要的组件渲染:避免在界面上渲染过多的组件,尤其是复杂的组件。可以使用条件渲染,只在需要的时候才渲染组件。优化图片和动画:使用压缩后的图片,并减少动画的使用,可以降低页面的加载时间和渲染压力。使用虚拟化技术:对于长列表,可以使用虚拟化技术,只渲染可视区域内的组件,提高滚动性能。
- API调用优化:使用缓存:对于相同参数的API调用,可以使用缓存,避免重复请求。压缩数据:在API调用中,尽量使用压缩后的数据,减少网络传输量。使用CDN:将静态资源部署到CDN上,可以加快资源的加载速度。
- 模型优化:选择更轻量级的模型:如果对声音特效的质量要求不高,可以选择更轻量级的模型,减少计算量。使用量化技术:对模型进行量化,可以降低模型的存储空间和计算量。使用模型剪枝技术:去除模型中不重要的连接,可以减少模型的参数量和计算量。
相关文章
