在人工智能领域,构建智能且高效的聊天机器人一直是研究的热点。传统的聊天机器人往往难以处理复杂、抽象的查询,并且容易产生“幻觉”,给出不准确或无关的信息。为了解决这些问题,Graph+RAG(图检索增强生成)技术应运而生。Graph+RAG结合了图数据库的强大关系建模能力和大型语言模型(LLM)的自然语言生成能力,能够提供更相关、更多样化、更连贯和更可靠的数据,从而生成更准确和更富事实性的文本。本篇博客将深入探讨Graph+RAG技术,并提供一个使用Langchain和GPT-4.0构建全本地聊天机器人的教程,帮助您为业务或个人应用打造强大的智能助手。
关键要点
- Graph+RAG通过图数据库存储和检索信息,能够更好地处理复杂关系和抽象查询。
- 相比传统RAG,Graph+RAG更不容易产生“幻觉”,提供更可靠的数据。
- Langchain是一个强大的框架,简化了LLM应用的构建过程。
- GPT-4.0提供了强大的自然语言理解和生成能力。
- Google发布Gemma 2,其性能可与Meta的Llama和Mistral的开源模型相媲美。
- 利用OpenAI函数从自然语言中提取结构化信息。
理解Graph+RAG的核心概念
什么是Graph+RAG?
Graph+RAG,即图检索增强生成,是一种将知识图谱与检索增强生成相结合的技术。简单来说,它利用图数据库来组织和存储信息,并利用图数据库的强大关系建模能力,使得LLM能够更有效地检索和利用相关信息,从而生成更准确、更连贯的回复。

在传统的RAG方法中,信息通常以文本块的形式存储,并通过向量相似度进行检索。然而,这种方法难以捕捉信息之间的复杂关系,容易导致LLM产生“幻觉”,生成不相关或不准确的回复。Graph+RAG通过将信息存储在图数据库中,能够清晰地表示实体之间的关系,从而使LLM能够更好地理解上下文,并生成更可靠的回复。
Graph+RAG的核心优势
- 更强的关系建模能力: 图数据库能够清晰地表示实体之间的复杂关系,使LLM能够更好地理解上下文。
- 更低的“幻觉”发生率: 通过利用图数据库的结构化信息,LLM能够更准确地检索和利用相关信息,从而降低“幻觉”的发生率。
- 更相关、更多样化、更连贯和更可靠的数据: 知识图谱提供了更多的相关、多样化、连贯和可靠的数据,为LLM生成高质量的文本提供了保障。
- 更好的可解释性: 图数据库的结构化信息使得模型的推理过程更具可解释性。
Graph+RAG与传统RAG的区别
虽然传统RAG方法在一定程度上能够提升LLM的性能,但其在处理复杂查询和关系推理方面存在局限性。Graph+RAG通过引入图数据库,弥补了这些不足,从而在以下几个方面优于传统RAG:
- 数据存储方式: 传统RAG通常以文本块的形式存储数据,而Graph+RAG则使用图数据库,以节点和边的形式存储数据,更好地表示实体之间的关系。
- 信息检索方式: 传统RAG主要依赖向量相似度进行信息检索,而Graph+RAG则利用图数据库的图遍历和查询能力,能够更有效地检索相关信息。
- 知识表示能力: Graph+RAG能够更清晰地表示实体之间的关系,提供更丰富的上下文信息,从而提升LLM的推理能力。
- 抗“幻觉”能力: Graph+RAG通过利用图数据库的结构化信息,降低了LLM产生“幻觉”的风险,提高回复的准确性和可靠性。
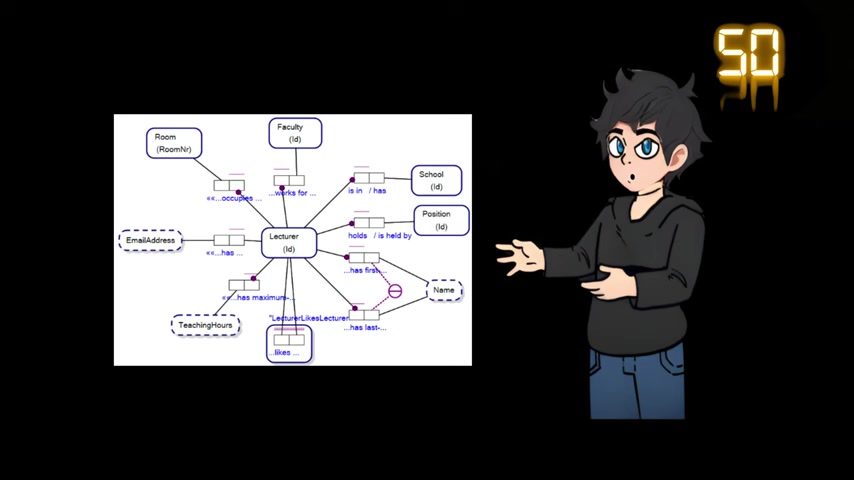
Graph+RAG的工作原理
Graph+RAG的工作流程可以概括为以下几个步骤:

- 数据存储: 首先,需要将数据导入到图数据库中。这通常涉及将文本数据转换为节点和边的形式,并定义实体之间的关系。例如,可以将一篇文章中的实体(如人名、地名、组织机构等)表示为节点,并将实体之间的关系(如“作者”、“位于”、“属于”等)表示为边。
- 查询处理: 当用户提出查询时,系统首先对查询进行语义分析,识别出查询中涉及的实体和关系。例如,对于查询“《哈利·波特》的作者是谁?”,系统需要识别出实体“《哈利·波特》”和关系“作者”。
- 信息检索: 接下来,系统利用图数据库的查询能力,检索与查询相关的节点和边。例如,可以从“《哈利·波特》”节点出发,沿着“作者”边找到对应的作者节点。
- 信息融合: 系统将检索到的节点和边信息进行融合,形成一个包含丰富上下文的知识片段。这个知识片段可以作为LLM的输入。
- 文本生成: 最后,LLM利用知识片段生成自然语言回复。例如,可以利用知识片段生成回复“《哈利·波特》的作者是J.K.罗琳”。
通过以上步骤,Graph+RAG能够有效地利用图数据库中的结构化信息,为LLM提供更准确、更全面的知识,从而生成更智能的回复。
打造Graph+RAG聊天机器人的步骤
步骤一:准备数据
首先,需要准备用于构建知识图谱的数据。数据可以来自各种来源,包括文本文件、PDF文件、网站、数据库等。数据的质量直接影响到知识图谱的质量,因此需要对数据进行清洗、整理和标准化。

数据准备的一些建议:
- 选择相关性高的数据源: 确保数据源包含与您的应用场景相关的信息。
- 进行数据清洗: 移除噪声数据、重复数据和错误数据。
- 进行数据标准化: 将数据转换为统一的格式,方便后续处理。
- 抽取实体和关系: 利用自然语言处理技术,从文本数据中抽取实体和关系。
步骤二:构建知识图谱
接下来,需要利用准备好的数据构建知识图谱。可以使用各种图数据库,例如Neo4j、JanusGraph等。构建知识图谱的过程包括以下几个步骤:
- 定义节点类型和属性: 确定知识图谱中需要表示的实体类型,并为每种实体类型定义相应的属性。例如,可以定义“人”、“地点”、“组织机构”等节点类型,并为“人”节点定义“姓名”、“年龄”、“职业”等属性。
- 定义关系类型和属性: 确定实体之间存在的关系类型,并为每种关系类型定义相应的属性。例如,可以定义“作者”、“位于”、“属于”等关系类型,并为“作者”关系定义“发表时间”等属性。
- 导入数据: 将准备好的数据导入到图数据库中,并根据定义的节点类型、属性和关系类型,创建相应的节点和边。
- 验证数据: 检查导入的数据是否正确,并进行必要的修改。

步骤三:构建RAG应用
然后,使用Langchain和GPT-4.0构建RAG应用。RAG应用的核心是将用户查询与知识图谱中的信息进行匹配,并将匹配结果作为LLM的输入,生成自然语言回复。构建RAG应用的过程包括以下几个步骤:
- 选择LLM: 选择合适的LLM,例如GPT-4.0。
- 构建查询引擎: 构建查询引擎,将用户查询转换为图数据库的查询语句。
- 检索相关信息: 利用查询引擎,从知识图谱中检索与用户查询相关的节点和边。
- 生成回复: 将检索到的节点和边信息作为LLM的输入,生成自然语言回复。
步骤四:优化和评估
最后,对RAG应用进行优化和评估。优化目标是提高回复的准确性、相关性和流畅性。评估方法包括人工评估和自动评估。优化和评估是一个迭代的过程,需要不断地调整模型参数、改进数据质量和优化查询引擎。
优化和评估的一些建议:
- 使用高质量的数据: 数据质量是RAG应用性能的关键因素。
- 选择合适的LLM: 不同的LLM在不同的任务上表现不同,需要根据应用场景选择合适的LLM。
- 优化查询引擎: 优化查询引擎,提高信息检索的准确性和效率。
- 进行人工评估: 邀请领域专家对回复进行评估,找出需要改进的地方。
- 进行自动评估: 使用自动评估指标,例如BLEU、ROUGE等,对回复进行评估。
Langchain安装指南:快速开始
安装Langchain
Langchain可以通过pip或conda进行安装。
推荐使用pip进行安装,因为它更简单易用。使用以下命令安装Langchain:
pip install langchain langchain-OpenAI tiktoken neo4j PyPDF2这个命令会安装Langchain及其依赖项,包括openai, tiktoken, neo4j和PyPDF2。您可以使用conda安装它,但是,如前所述,首选pip。强烈建议升级这些软件包。使用pip,您将运行:
pip install --upgrade langchain langchain-openai tiktoken neo4j PyPDF2设置Neo4j
Langchain需要访问Neo4j数据库才能存储和检索知识图谱。有两种方法可以设置Neo4j:
- 使用Neo4j AuraDB: Neo4j AuraDB是Neo4j提供的云数据库服务,可以免费创建一个数据库实例。要使用Neo4j AuraDB,您需要注册一个账号,并创建一个数据库实例。然后,您需要获取数据库的连接信息,包括URL、用户名和密码。
- 安装本地Neo4j: 您也可以在本地安装Neo4j数据库。要安装本地Neo4j,您需要从Neo4j官网下载安装包,并按照安装指南进行安装。安装完成后,您需要启动Neo4j数据库,并获取数据库的连接信息。

例如:
url = "bolt://localhost:7687"
username = "neo4j"
password = "letmein"设置环境变量
接下来你需要设置你的OpenAI API Key和你的Neo4j数据库。这允许代码安全地访问必要的服务。这可以通过直接在代码中指定或通过环境变量来完成。我们来演示如何在代码中设置它。这被认为是不安全的,因为您可能不小心提交了您的密钥。永远不要在你的代码中提交密钥。
import os
import openai
os.environ["OPENAI-API-KEY"] = "Your_api"
openai.api_key = os.getenv("OPENAI-API-KEY")
url = "bolt://localhost:7687"
username = "neo4j"
password = "letmein"在环境变量中设置API密钥提供了一种更安全的替代方案。此方法将API密钥存储在系统的环境变量中,从而使密钥不会直接暴露在代码中。要访问Python中的环境变量,可以使用os模块。首先,设置环境变量:
export OPENAI_API_KEY="你的OpenAI API密钥"或者
export NEO4J_URI="bolt://localhost:7687"
export NEO4J_USERNAME="neo4j"
export NEO4J_PASSWORD="letmein"然后,在你的Python脚本中,使用os.environ来访问这些环境变量:
import os
os.environ["OPENAI-API-KEY"] = "你的OpenAI API密钥"
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "letmein"
url = os.environ["NEO4J_URI"]
username = os.environ["NEO4J_USERNAME"]
password = os.environ["NEO4J_PASSWORD"]通过这种方式,API密钥不会硬编码到你的脚本中,这可以防止敏感信息泄露。
Graph+RAG的优缺点分析
优点
- 能够处理复杂、抽象的查询
- 降低“幻觉”发生率
- 提供更相关、更多样化、更连贯和更可靠的数据
- 具有更好的可解释性
缺点
- 构建和维护知识图谱需要一定的成本
- 需要一定的图数据库技术
- 对数据质量要求较高
Langchain和GPT-4.0的核心功能
Langchain
Langchain是一个用于构建基于LLM的应用的框架,它提供了以下核心功能:
- 模型集成: Langchain支持与各种LLM集成,包括OpenAI、Google AI、Meta等。
- 数据连接: Langchain提供了各种数据连接器,可以从各种数据源加载数据,包括文本文件、PDF文件、网站、数据库等。
- 链式调用: Langchain允许将多个LLM和数据连接器组合成一个链式调用,实现复杂的信息处理流程。
- 代理: Langchain提供了代理功能,可以根据用户的输入自动选择合适的工具和模型,完成复杂的任务。
通过利用Langchain的这些功能,可以简化LLM应用的构建过程,并提高应用的灵活性和可扩展性。
GPT-4.0
GPT-4.0是OpenAI开发的强大的LLM,它具有以下核心功能:
- 强大的自然语言理解能力: GPT-4.0能够理解复杂的自然语言输入,并准确地识别出用户的意图。
- 高质量的文本生成能力: GPT-4.0能够生成高质量、连贯、流畅的自然语言文本。
- 强大的知识储备: GPT-4.0拥有庞大的知识储备,能够回答各种领域的问题。
- 多模态能力: GPT-4.0支持多模态输入,可以处理文本、图像等多种类型的数据。
GPT-4.0的这些功能使得它成为构建智能聊天机器人的理想选择。
Graph+RAG的典型应用场景
企业知识库问答
企业可以使用Graph+RAG技术构建智能知识库问答系统,帮助员工快速找到所需信息。例如,员工可以通过自然语言查询,快速找到公司政策、产品信息、技术文档等。
相关文章
