人工智能(AI)正在迅速渗透到医疗领域的各个角落,尤其在临床诊断决策方面,AI的应用展现出巨大的潜力。AI模型能够快速处理海量医疗数据,辅助医生进行更精确、高效的诊断,从而改善患者的治疗效果。然而,我们必须清醒地认识到,AI并非完美无瑕,其固有的“黑箱”特性以及潜在的偏见风险,给AI在医疗领域的应用带来了严峻的挑战。如果AI模型存在偏见,那么它所提供的诊断建议可能会对特定人群造成伤害,加剧医疗资源分配的不公,甚至引发伦理问题。因此,如何有效地应对AI模型偏见,确保AI在医疗领域中的安全、公平应用,是当前亟待解决的关键问题。本文将深入探讨AI模型偏见在临床诊断决策中的表现,分析其产生的原因,并结合实际案例,探讨如何通过各种策略来缓解或消除这些偏见,从而帮助临床医生更好地利用AI技术,做出更明智、更准确的诊断和治疗决策。
核心要点
- AI模型在临床诊断决策中具有巨大潜力,但也存在偏见风险。
- AI模型偏见可能导致诊断不准确、医疗资源分配不公等问题。
- 可解释性AI(XAI)是应对AI模型偏见的重要手段。
- 缓解AI模型偏见需要结合计算方法和人机协作。
- 加强AI医疗领域的伦理培训和监管至关重要。
AI医疗诊断的现状与挑战
AI在临床诊断决策中的应用
AI在临床诊断决策中的应用日益广泛,其强大的数据处理和分析能力,能够帮助医生:
- 快速分析海量数据:AI模型可以迅速处理医学影像、基因组数据、电子病历等海量信息,从中提取有价值的特征,为诊断提供更全面的依据。
- 提高诊断准确率:通过机器学习算法,AI模型能够识别人类医生难以发现的细微病灶,降低误诊率,提高诊断准确性。
- 优化治疗方案:AI模型可以根据患者的个体特征,预测治疗效果,辅助医生制定更个性化的治疗方案,从而提高治疗成功率。
然而,AI在医疗诊断领域中的应用并非一帆风顺。AI模型是基于大量数据训练而成的,如果训练数据本身存在偏见,那么AI模型也会继承这些偏见,导致对特定人群的诊断结果不准确,甚至产生歧视。例如,如果AI模型主要使用男性患者的数据进行训练,那么它在诊断女性患者时可能会出现偏差,导致女性患者被误诊或漏诊。

AI模型偏见的表现
AI模型偏见在临床诊断决策中的表现形式多种多样,主要包括以下几个方面:
- 性别偏见:AI模型在诊断心脏病时,容易忽视女性患者的症状,导致女性患者被低估或延迟诊断。
- 种族偏见:脉搏血氧仪在测量血氧饱和度时,对肤色较深的患者存在误差,可能导致黑人患者无法及时获得治疗。
- 数据偏差:如果AI模型的训练数据主要来自特定地区或特定人群,那么它在应用于其他地区或人群时可能会出现偏差。
- 年龄偏差:比如针对老年人群体的疾病,如果在数据集里老年人的数据较少,模型可能无法准确识别老年人特有的疾病特征,从而导致误诊。

AI模型偏见的成因分析
AI模型偏见的产生并非偶然,而是多种因素共同作用的结果:
- 数据来源偏差:AI模型的训练数据是其做出判断的基础,如果数据来源存在偏差,例如数据收集范围有限、数据采集方式不合理、数据标注存在错误等,那么AI模型也会受到影响,从而产生偏见。
- 算法设计缺陷:某些算法在设计上可能存在缺陷,例如对特定特征过于敏感、对特定人群的特征学习不足等,这些缺陷会导致AI模型在处理不同人群的数据时产生差异。
- 社会文化因素:AI模型在训练过程中,可能会受到社会文化因素的影响,例如对某些人群的刻板印象、对某些疾病的污名化等,这些因素会导致AI模型产生歧视性的判断。
- 人类自身的认知局限:在构建AI模型时,人类自身的认知局限也可能导致偏见的产生。例如,医生对某些疾病的认识可能存在偏差,这些偏差会反映在AI模型的训练数据中,从而影响AI模型的判断。
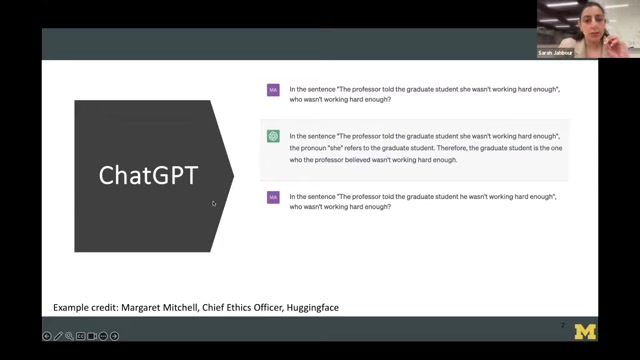
如何缓解AI医疗诊断中的模型偏见?
确保训练数据的多样性和代表性
训练数据是AI模型的基础,只有确保训练数据的多样性和代表性,才能有效避免AI模型产生偏见。具体措施包括:
- 扩大数据收集范围:尽可能收集来自不同地区、不同种族、不同性别、不同年龄段的数据,确保AI模型能够接触到更广泛的患者群体。
- 采用科学的数据采集方法:在数据采集过程中,要严格遵守伦理规范,避免引入不必要的偏差,例如,避免对某些人群进行过度采样或过度报道。
- 进行数据清洗和预处理:对收集到的数据进行清洗和预处理,去除错误数据、异常数据,纠正数据标注中的错误,从而提高数据的质量和可靠性。
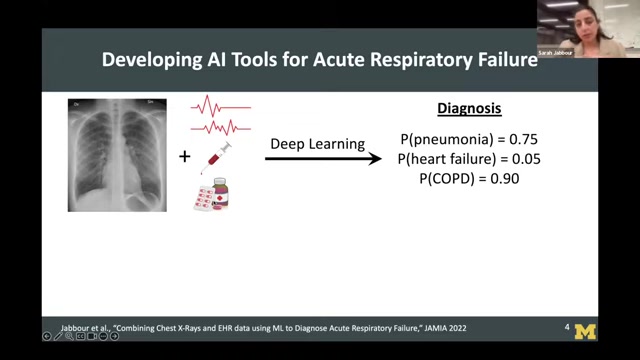
利用可解释性AI(XAI)技术
可解释性AI(XAI)技术能够帮助我们理解AI模型做出决策的原因,从而发现潜在的偏见。XAI技术主要包括以下几个方面:
- 特征重要性分析:通过分析AI模型中不同特征的重要性,可以了解哪些特征对诊断结果影响最大,从而发现AI模型是否过度依赖某些特定特征。
- 决策规则提取:通过提取AI模型的决策规则,可以了解AI模型是如何将不同特征组合起来进行判断的,从而发现AI模型是否存在歧视性的决策逻辑。
- 可视化技术:通过将AI模型的决策过程可视化,可以帮助医生更直观地理解AI模型的判断依据,从而发现AI模型是否存在偏差。

加强人机协作
AI在医疗领域中的应用,并非要取代医生,而是要辅助医生做出更好的决策。要确保AI模型偏见不会对患者造成伤害,需要加强人机协作,充分发挥医生的专业知识和经验。具体措施包括:
- 医生审核AI模型的诊断结果:医生在参考AI模型提供的诊断建议时,要结合自身的临床经验,对AI模型的诊断结果进行独立审核,确保其合理性。
- 医生参与AI模型的开发和评估:医生应该积极参与AI模型的开发和评估过程,帮助AI研究人员更好地理解临床需求,从而开发出更符合实际需求的AI模型。
- 建立完善的反馈机制:建立完善的反馈机制,鼓励医生对AI模型提出的错误建议进行反馈,从而帮助AI研究人员及时发现和修复AI模型中的问题。
如何安全使用AI医疗诊断模型
- 选择合适的AI模型:在选择AI模型时,要充分考虑其适用范围、性能指标、潜在风险等因素,选择经过充分验证、性能稳定、风险可控的AI模型。
- 正确理解AI模型的输出结果:AI模型的输出结果仅为参考,不能作为唯一的诊断依据。医生需要结合患者的病史、体征、实验室检查等信息,进行综合判断。
- 注意AI模型的适用人群:不同的AI模型可能适用于不同的人群,医生在使用AI模型时,需要了解其适用人群,避免对不适用的人群进行诊断。
- 持续监控AI模型的表现:AI模型的性能可能会随着时间推移而下降,医生需要定期监控AI模型的表现,及时发现和解决问题。
- 建立完善的伦理规范和监管机制:为确保AI在医疗领域中的安全、公平应用,需要建立完善的伦理规范和监管机制,明确AI模型的开发、使用、维护等方面的责任和义务。
常见问题
如何判断AI模型是否存在偏见?
可以通过多种方法来判断AI模型是否存在偏见,例如:
- 分析训练数据:检查训练数据是否包含特定人群的数据量不足、数据分布不均衡等问题。
- 评估AI模型在不同人群中的性能:分别评估AI模型在不同性别、不同种族、不同年龄段等人群中的准确率、召回率等指标,观察是否存在显著差异。
- 使用可解释性AI技术:利用XAI技术,了解AI模型是如何将不同特征组合起来进行判断的,从而发现AI模型是否存在歧视性的决策逻辑。
如何缓解AI模型偏见?
缓解AI模型偏见需要从多个角度入手,主要包括:
- 确保训练数据的多样性和代表性:尽可能收集来自不同地区、不同种族、不同性别、不同年龄段的数据,确保AI模型能够接触到更广泛的患者群体。
- 采用科学的数据采集方法:在数据采集过程中,要严格遵守伦理规范,避免引入不必要的偏差,例如,避免对某些人群进行过度采样或过度报道。
- 进行数据清洗和预处理:对收集到的数据进行清洗和预处理,去除错误数据、异常数据,纠正数据标注中的错误,从而提高数据的质量和可靠性。
- 选择合适的算法:某些算法在设计上可能存在缺陷,例如对特定特征过于敏感、对特定人群的特征学习不足等,这些缺陷会导致AI模型在处理不同人群的数据时产生差异。因此,在选择算法时,要充分考虑其适用范围和潜在风险。
- 使用可解释性AI技术:可解释性AI(XAI)技术能够帮助我们理解AI模型做出决策的原因,从而发现潜在的偏见。
AI在医疗诊断领域中的应用前景如何?
AI在医疗诊断领域中的应用前景十分广阔,未来有望在以下几个方面发挥重要作用:
- 辅助医生进行诊断:AI模型可以帮助医生快速分析海量数据,提供更全面、更准确的诊断建议,从而提高诊断效率和准确率。
- 实现个性化治疗:AI模型可以根据患者的个体特征,预测治疗效果,辅助医生制定更个性化的治疗方案,从而提高治疗成功率。
- 促进医疗资源公平分配:AI模型可以应用于远程医疗、移动医疗等场景,将优质的医疗资源输送到偏远地区和欠发达地区,从而促进医疗资源公平分配。
- 加速新药研发:AI模型可以用于分析药物的有效性和安全性,预测药物的副作用,从而加速新药研发进程,降低研发成本。
然而,要实现这些愿景,我们需要解决AI模型偏见、数据安全、伦理道德等一系列问题,确保AI在医疗领域中的应用能够真正造福人类。
相关问题
如何评估AI模型在医疗诊断中的表现?
评估AI模型在医疗诊断中的表现,需要综合考虑多个指标,主要包括:
- 准确率(Accuracy):AI模型预测正确的样本数占总样本数的比例,反映了AI模型的整体预测能力。
- 精确率(Precision):AI模型预测为阳性的样本中,实际为阳性的样本数占总预测为阳性的样本数的比例,反映了AI模型预测阳性的准确程度。
- 召回率(Recall):实际为阳性的样本中,AI模型预测为阳性的样本数占总实际为阳性的样本数的比例,反映了AI模型识别阳性的能力。
- F1值(F1-score):综合考虑精确率和召回率的指标,反映了AI模型整体性能的平衡性。
- AUC值(Area Under Curve):ROC曲线下的面积,反映了AI模型区分正负样本的能力。
除了上述指标,还需要考虑AI模型在不同人群中的性能表现,以及AI模型的可解释性、鲁棒性等因素。
更详细的信息
在评价和比较医学诊断模型的性能时,有几个指标非常关键。以下是一些核心指标及其在医学背景下的详细解释,以及如何进行有效的数据解读:
- 混淆矩阵 (Confusion Matrix):混淆矩阵是评估分类模型性能的基础,尤其在医学诊断中非常重要,因为它可以详细展示模型在不同类别上的表现。它包含以下四个关键元素:
- 真阳性 (True Positive, TP): 模型正确预测为阳性的样本数。在医学诊断中,表示模型正确识别出的患病个体数量。
- 真阴性 (True Negative, TN): 模型正确预测为阴性的样本数。在医学诊断中,表示模型正确识别出的未患病个体数量。
- 假阳性 (False Positive, FP): 模型错误预测为阳性的样本数。在医学诊断中,表示模型错误地将未患病个体诊断为患病(也称为I型错误)。
- 假阴性 (False Negative, FN): 模型错误预测为阴性的样本数。在医学诊断中,表示模型未能识别出的患病个体数量(也称为II型错误)。
数据解读:在医学领域,假阴性(FN)通常比假阳性(FP)更危险,因为漏诊可能导致患者延误治疗,病情恶化。因此,在评估模型时,需要特别关注假阴性率。
- 准确率 (Accuracy):公式:(TP + TN) / (TP + TN + FP + FN)。解释:准确率是所有预测正确的样本数与总样本数之比,衡量模型整体预测的正确程度。然而,在类别不平衡的数据集中(例如罕见疾病的诊断),高准确率可能具有误导性。想象一下,如果一个疾病的发生率只有1%,即使模型将所有样本都预测为阴性,其准确率也能达到99%,但这显然不是一个有用的模型。
- 精确率 (Precision):公式:TP / (TP + FP)。解释:精确率是指所有被模型预测为阳性的样本中,真正为阳性的比例。精确率越高,说明模型误诊的比例越低。在医学诊断中,高精确率意味着减少不必要的检查或治疗,例如减少不必要的手术。
- 召回率 (Recall):公式:TP / (TP + FN)。解释:召回率是指所有实际为阳性的样本中,被模型正确预测为阳性的比例。召回率越高,说明模型漏诊的比例越低。在医学诊断中,高召回率意味着尽可能多地识别出患病个体,避免漏诊。
- F1 分数 (F1-Score):公式:2 * (Precision * Recall) / (Precision + Recall)。解释:F1分数是精确率和召回率的调和平均数,综合衡量模型的精确率和召回率。它提供了一个平衡的视角,尤其在类别不平衡时非常有用。
- ROC 曲线与 AUC 值:ROC 曲线 (Receiver Operating Characteristic Curve): ROC曲线以假阳性率(False Positive Rate, FPR)为横轴,真阳性率(True Positive Rate, TPR,即召回率)为纵轴绘制的曲线。ROC曲线展示了在不同阈值下,模型区分正负样本的能力。AUC 值 (Area Under the Curve): AUC值是ROC曲线下的面积,取值范围在0.5到1之间。AUC值越高,说明模型区分正负样本的能力越强。数据解读:ROC曲线和AUC值常用于评估二分类模型的性能。一个好的模型应该具有较高的AUC值,ROC曲线尽可能靠近左上角。AUC=0.5的模型相当于随机猜测,而AUC=1的模型则完美地区分了正负样本。
- 其他重要考量:除了上述指标,以下因素在评估医学诊断模型时也至关重要:
- 特异性 (Specificity): 模型正确预测为阴性的样本数占所有实际为阴性的样本数之比。高特异性意味着模型很少将健康个体误诊为患病。
- 阴性预测值 (Negative Predictive Value, NPV): 在所有预测为阴性的样本中,真正为阴性的比例。高NPV意味着如果模型预测你没有患病,那么你确实没有患病的可能性很高。
- 阳性预测值 (Positive Predictive Value, PPV): 在所有预测为阳性的样本中,真正为阳性的比例。高PPV意味着如果模型预测你患病,那么你真正患病的可能性很高。
- 临床实用性:模型是否易于使用,是否能够融入现有的临床工作流程。一个性能优异但难以使用的模型在实际应用中价值有限。
- 成本效益:模型的使用成本(包括硬件、软件、维护、培训等)是否合理,是否能够带来显著的经济效益。
数据解读的注意事项:
- 结合具体场景:不同的医学诊断任务对模型性能的要求不同。例如,对于筛查任务,可能更看重召回率,以避免漏诊;对于确诊任务,可能更看重精确率,以减少误诊。
- 考虑类别不平衡:在类别不平衡的数据集中,需要特别关注精确率、召回率和F1分数,而不仅仅是准确率。
- 关注置信区间:评估指标通常会提供置信区间,置信区间越窄,说明评估结果越可靠。
- 进行外部验证:使用独立的数据集对模型进行验证,以评估模型的泛化能力。
总的来说,对医学诊断模型进行全面的性能评估需要综合考虑多个指标,并结合具体的应用场景和临床需求。
相关文章
