在人工智能 (AI) 领域,Hugging Face Transformers 库为用户提供了一种简单而强大的方法来利用预训练模型。其中,Pipelines 功能更是将模型推理过程简化到了极致,即使是编程新手也能快速上手。本文将深入介绍 Hugging Face Pipelines 的使用方法,并以 DeepSeek AI 大模型为例,讲解如何在 Google Colab 中加载和使用这些强大的模型。
Hugging Face Pipelines 关键要点
- Pipelines 提供了一种使用预训练模型进行推理的简单方法。
- 可以使用 Pipelines 加载各种不同的模型,包括文本生成、情感分析和图像分类模型。
- AutoClass 是一种更灵活的方法,允许您访问模型的更多底层细节。
- 使用 DeepSeek AI 模型可以实现强大的文本生成和代码生成功能。
- Google Colab 提供了一个方便的环境来运行和实验 AI 模型。
Hugging Face Pipelines 基础
什么是 Hugging Face Pipelines?Hugging Face Pipelines 是一种高级 API,旨在简化使用预训练模型进行各种自然语言处理 (NLP) 和计算机视觉 (CV) 任务的过程。Pipeline 将模型、分词器和预处理步骤封装在一起,使用户只需几行代码即可完成复杂的任务。
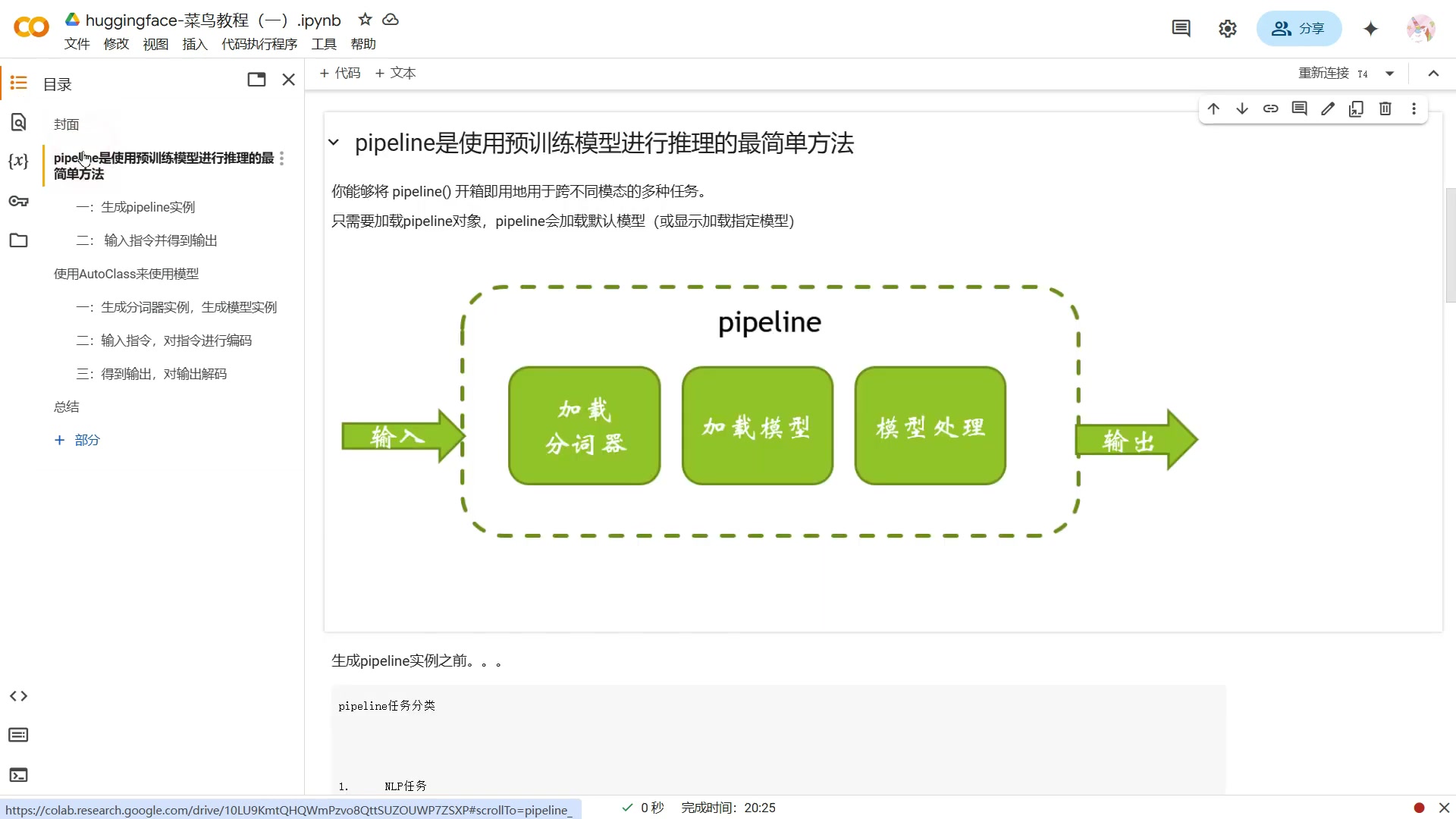
它提供了加载分词器,加载模型,模型处理的过程。我们只需要生成一个 Pipeline 实例,然后给这个 pipeline 实例输入一个指令,这个 pipeline 就会根据我们的要求给出一个输出。
Pipelines 的优势
- 易于使用:Pipelines 提供了一个简单直观的 API,即使是初学者也能快速上手。
- 高度抽象:Pipelines 隐藏了模型加载、预处理和推理的复杂性,让用户专注于任务本身。
- 灵活性:Pipelines 支持各种不同的模型和任务,并且可以轻松定制。
- 高效性:Pipelines 经过优化,可以高效地执行推理任务。
Pipelines 的主要组件
- 模型 (Model): 用于执行实际推理的预训练模型。
- 分词器 (Tokenizer): 用于将文本转换为模型可以理解的格式。
- 预处理器 (Preprocessor): 用于对输入数据进行预处理,例如调整图像大小或填充文本序列。
在 Google Colab 中使用 DeepSeek AI 模型
安装 Transformers 库
首先,需要在 Google Colab 中安装 transformers 库。可以使用以下命令:
!pip install transformers该命令会自动下载和安装 transformers 库及其依赖项。
在 core 里面安装这个 transformer 库。transformers 库包含了使用 DeepSeek AI 模型所需的工具和函数。
加载 DeepSeek AI 模型
加载预训练的 DeepSeek AI 模型。这里需要指定 task 为 text-generation,并提供 deepseek AI 模型的名称:
from transformers import pipeline
generator = pipeline('text-generation', model='deepseek-ai/DeepSeek-Coder')model 参数指定要使用的 DeepSeek AI 模型。DeepSeek-Coder 是一个强大的代码生成模型,可以根据给定的指令生成代码。
使用模型生成文本
加载模型后,就可以使用它来生成文本了。只需提供一个提示 (Prompt),模型将根据该提示生成后续文本:
res = generator("你好,我需要解决个问题,如何将一个圆平分成四个相等的区域?")
print(res)这行代码会生成一段文本。可以通过更改提示来控制生成的文本。

DeepSeek AI 模型与其他方法结合使用
使用 AutoClass 加载模型
除了使用 Pipelines,还可以使用 AutoClass 加载 DeepSeek AI 模型。AutoClass 提供了一种更灵活的方式来访问模型的底层细节,并允许您自定义模型的行为。使用 AutoClass 需要更多的代码,但也提供了更多的控制权。
加载模型和分词器
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "deepseek-ai/DeepSeek-Coder"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)使用模型生成文本
prompt = "写一段美女的特质。"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_length=50)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)Hugging Face Pipelines 的优缺点
👍 Pros
- 易于使用
- 高度抽象
- 灵活性
- 高效性
👎 Cons
- 定制性有限
- 可能难以访问底层细节
常见问题解答
什么是 Hugging Face?
Hugging Face 是一家专注于自然语言处理 (NLP) 的公司,提供各种工具和资源,帮助开发者构建 AI 应用。其最著名的产品是 Transformers 库,其中包含了各种预训练模型和 Pipelines。
DeepSeek AI 模型有哪些?
DeepSeek AI 开发了一系列强大的语言模型,尤其在代码生成方面表现出色。其中 DeepSeek-Coder 是一个备受关注的模型,能够根据指令生成高质量的代码。
我需要 GPU 才能运行 DeepSeek AI 模型吗?
虽然可以使用 CPU 运行 DeepSeek AI 模型,但使用 GPU 可以显著提高推理速度。Google Colab 提供了免费的 GPU 资源,是运行这些模型的理想选择。
相关问题
如何选择合适的预训练模型?
选择预训练模型时,需要考虑以下因素:任务类型、模型大小、性能和资源限制。Hugging Face Hub 提供了各种预训练模型,可以根据需要进行选择。不同的预训练模型使用不同的语言数据集和文本,比如中文,英文,必须注意模型训练时候使用的文本,才能避免结果出现差异。
相关文章
