在人工智能领域,大模型的应用日益普及。然而,对于许多开发者来说,如何高效地加载和使用这些模型仍然是一个挑战。幸运的是,Hugging Face 的 Transformers 库提供了一种名为 Pipelines 的强大工具,它极大地简化了这一过程。本篇博客将带您深入了解 Hugging Face Pipelines,并通过具体示例,展示如何在 Google Colab 中加载和使用 DeepSeek 等大模型,让您轻松入门大模型应用。Hugging Face Transformers 库是目前最流行的自然语言处理 (NLP) 库之一。它不仅提供了各种预训练模型,还提供了 Pipelines 这一便捷工具,让开发者能够以最简单的方式使用这些模型。Pipelines 封装了模型加载、预处理、推理和后处理等步骤,让开发者只需几行代码即可完成复杂的 NLP 任务。本博客将重点介绍 Pipelines 的使用方法,包括如何创建 Pipeline 实例、如何输入指令并获得输出,以及如何利用 AutoClass 来使用模型。同时,我们还将探讨在 Google Colab 中使用 Pipelines 加载和使用 DeepSeek 大模型的具体步骤。通过本博客,您将能够掌握使用 Pipelines 简化大模型应用的技巧,为您的 AI 项目注入新的活力。
Hugging Face Pipelines 关键要点
- Pipelines 简化了大模型的使用流程。
- Transformers 库提供了丰富的预训练模型。
- AutoClass 可以自动加载合适的模型。
- Google Colab 是一个便捷的 AI 开发平台。
- DeepSeek 是一个强大的大模型。
Hugging Face Pipelines 核心概念与应用
什么是 Hugging Face Pipelines?
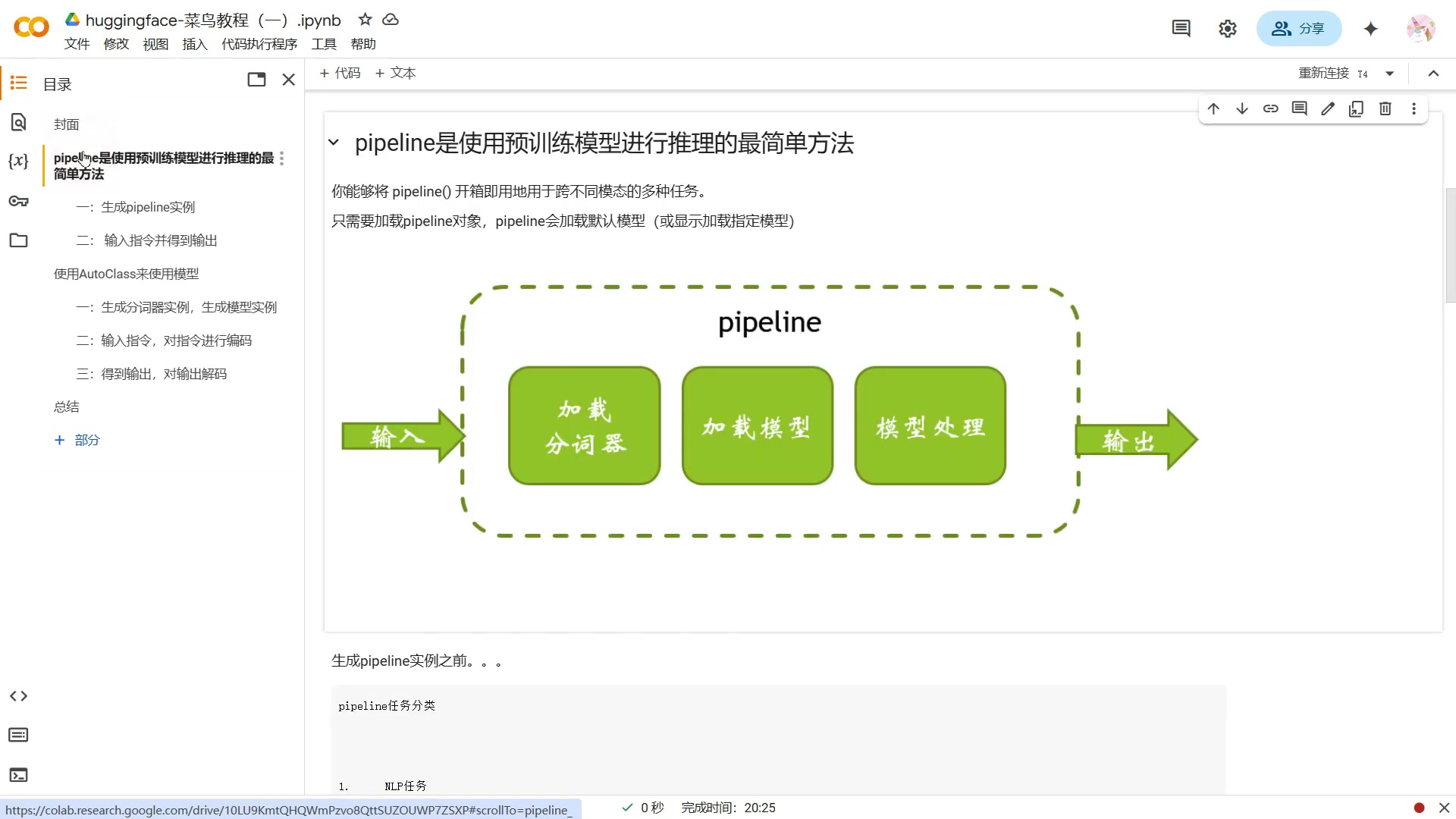
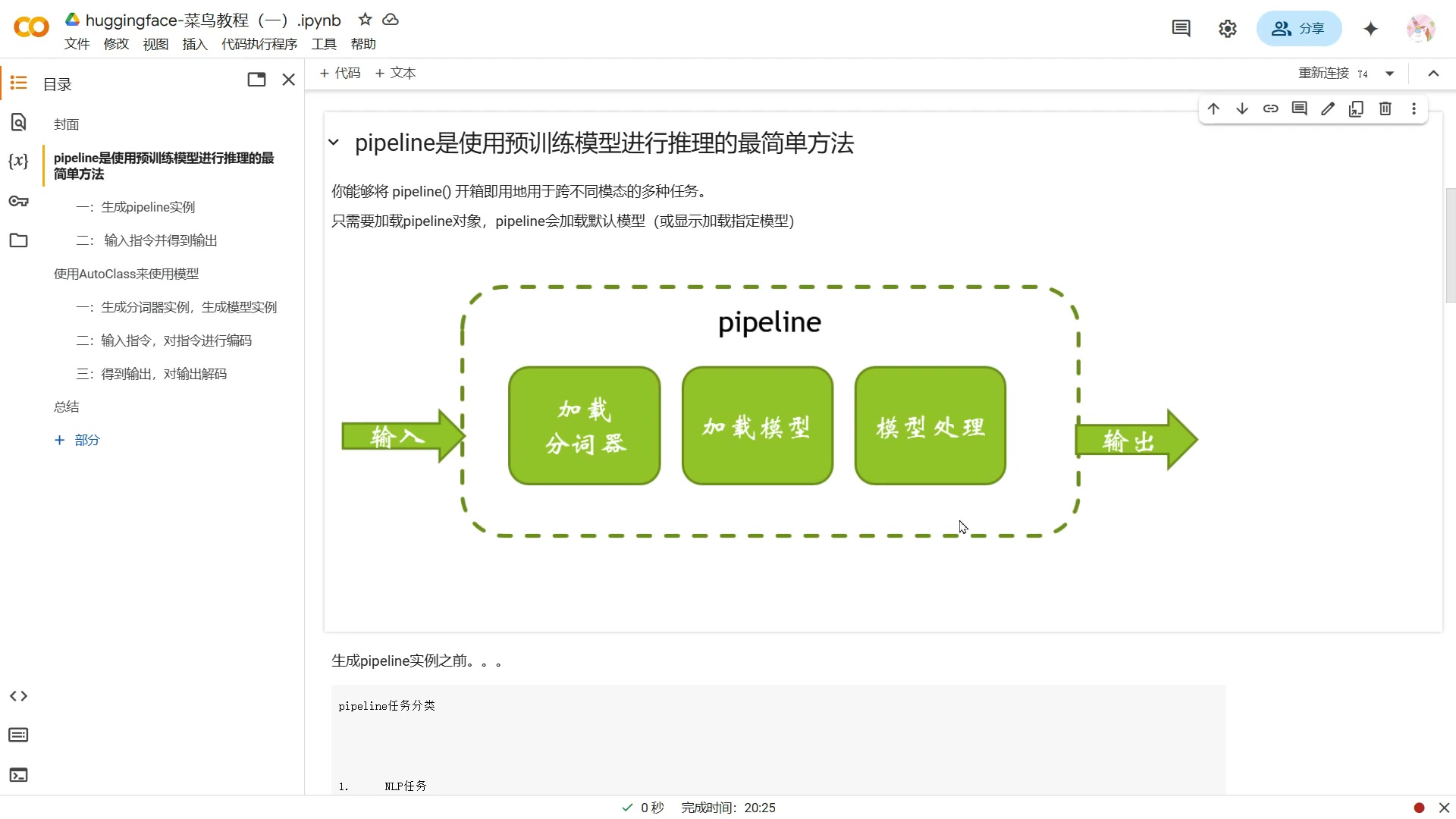
Hugging Face Pipelines 是 Transformers 库中的一个高级 API,旨在简化预训练模型的使用。它将复杂的模型加载、预处理、推理和后处理步骤封装成一个单一的接口,使得开发者能够以最简单的方式使用各种 NLP 模型。
Pipelines 的核心优势:
- 易用性:Pipelines 提供了简洁的 API,只需几行代码即可完成复杂的 NLP 任务。
- 灵活性:Pipelines 支持各种 NLP 任务,如文本分类、文本生成、问答等。
- 可扩展性:Pipelines 可以轻松地集成自定义模型和预处理/后处理逻辑。
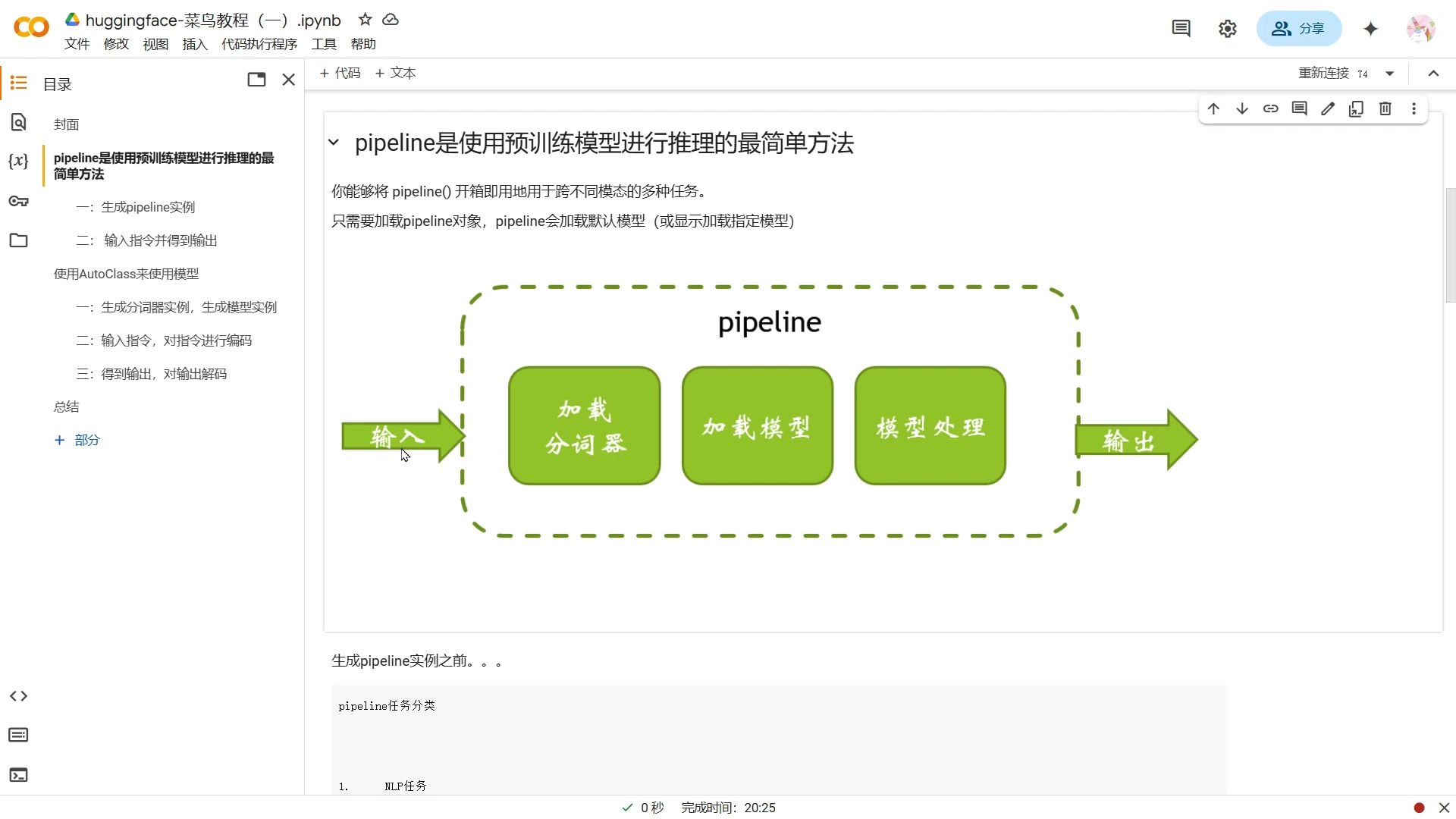
Pipeline 的工作流程:
- 加载模型:Pipelines 会自动加载预训练模型和相应的分词器。
- 预处理:Pipelines 会将输入文本转换为模型所需的格式。
- 推理:Pipelines 会将预处理后的输入传递给模型进行推理。
- 后处理:Pipelines 会将模型的输出转换为易于理解的格式。
Pipelines 的两种使用方式
Transformer 库提供两种核心的使用大模型的方式:
- 使用 Pipeline:这是最简单的方式,它封装了所有底层细节,让您能够以最少的代码完成任务。
- 使用 AutoClass:这种方式更加灵活,允许您自定义模型加载和处理过程。
本博客将重点介绍如何使用 Pipeline 简化大模型应用。
Google Colab 中加载和使用 DeepSeek 大模型
DeepSeek 大模型简介
DeepSeek 是由 DeepSeek AI 开发的一款强大的大模型,它在代码生成、文本生成和推理等任务上都表现出色。DeepSeek 具有以下特点:
- 强大的性能:DeepSeek 在各种 NLP 任务上都取得了领先的结果。
- 高效的推理:DeepSeek 经过优化,可以在各种硬件平台上高效地进行推理。
- 易于使用:DeepSeek 提供了简洁的 API,方便开发者使用。
DeepSeek R1:
这个模型是 DeepSeek AI 推出的,主要设计用于自然语言的生成式任务。它通过预训练的方式学习语言的模式,可以用于创造性写作、文本摘要和对话生成等多种应用场景。该模型特别适用于需要生成流畅、连贯文本的应用。
DeepSeek-Coder:
这是 DeepSeek AI 专门为代码生成任务设计的模型。它通过大量的代码数据进行训练,能够理解编程语言的结构和语义,可以用于自动生成代码片段、代码补全和代码翻译等应用。该模型非常适合开发辅助工具,可以帮助开发者提高编码效率。
使用 Pipelines 加载 DeepSeek
在 Google Colab 中使用 Pipelines 加载 DeepSeek 非常简单。首先,您需要安装 Transformers 库:
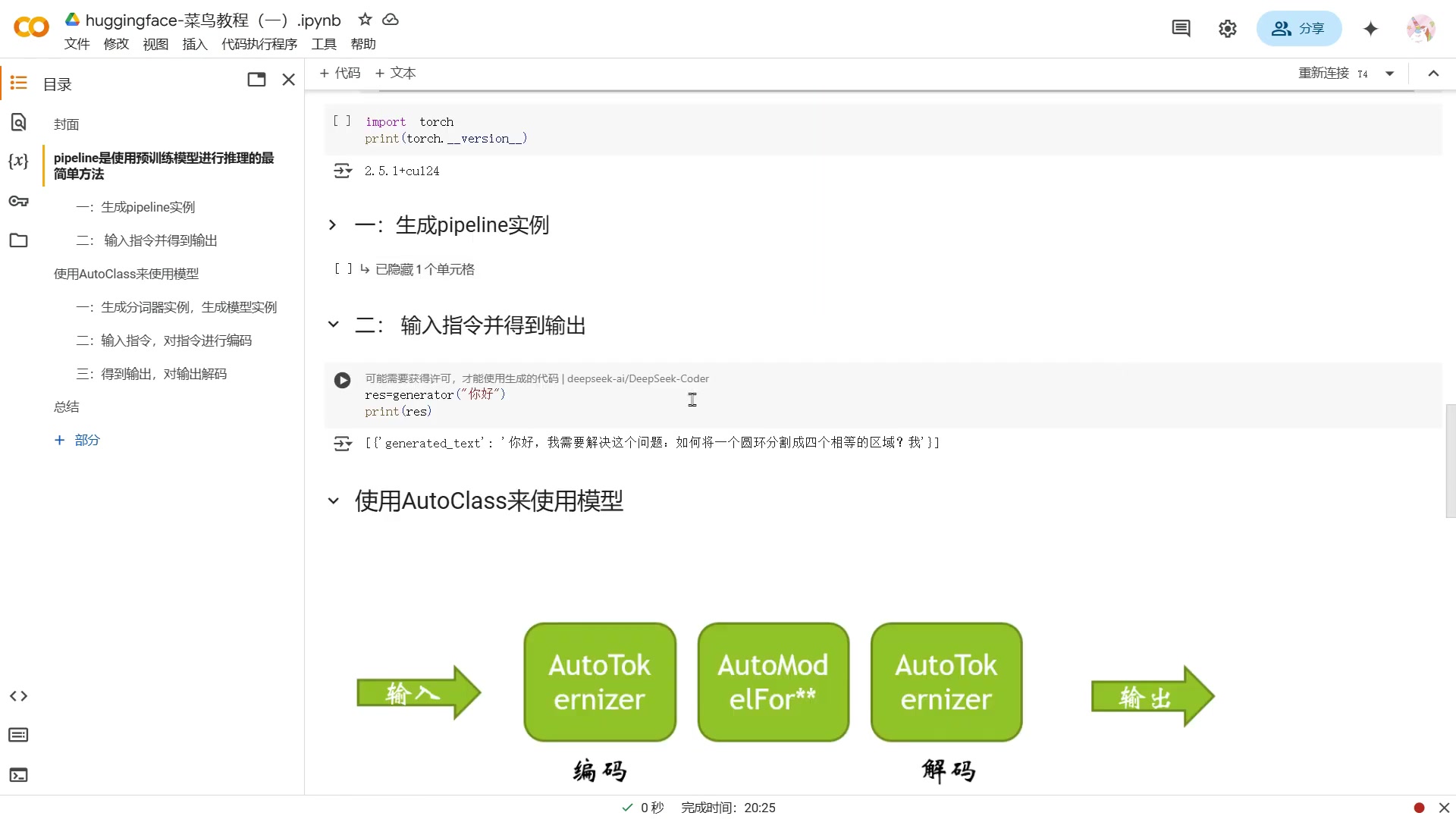
!pip install transformers然后,您可以创建一个 Pipeline 实例,并指定要使用的模型:
from transformers import pipeline
generator = pipeline('text-generation', model='deepseek-ai/DeepSeek-Coder')现在,您可以输入指令并获得输出了:
print(generator('请写一段关于夏天的文字'))Pipelines 会自动下载 DeepSeek 模型,并生成一段关于夏天的文字。是不是非常简单?
使用 Pipelines 的步骤详解
步骤 1:安装 Transformers 库
要使用 Hugging Face Pipelines,首先需要安装 Transformers 库。在 Google Colab 中,可以使用以下命令安装:
!pip install transformers这条命令会从 PyPI 下载并安装 Transformers 库及其依赖项。
步骤 2:创建 Pipeline 实例
安装完成后,您需要创建一个 Pipeline 实例。Pipeline 类的构造函数接受多个参数,其中最重要的参数是 task 和 model。
task 参数指定要执行的 NLP 任务,例如 'text-generation'(文本生成)、'sentiment-analysis'(情感分析)等。model 参数指定要使用的预训练模型。如果您不指定 model 参数,Pipeline 会自动加载一个默认模型。
以下是一些 Pipeline 实例的示例:
from transformers import pipeline
# 创建一个文本生成 Pipeline
generator = pipeline('text-generation', model='deepseek-ai/DeepSeek-Coder')
# 创建一个情感分析 Pipeline
classifier = pipeline('sentiment-analysis')步骤 3:输入指令并获得输出
创建 Pipeline 实例后,您就可以输入指令并获得输出了。Pipeline 实例的调用方式与普通函数类似,只需将输入文本作为参数传递给它即可。
from transformers import pipeline
generator = pipeline('text-generation', model='deepseek-ai/DeepSeek-Coder')
# 输入指令并获得输出
output = generator('请写一段关于夏天的文字')
print(output)Pipelines 会自动对输入文本进行预处理、推理和后处理,并将结果以易于理解的格式返回。
DeepSeek 大模型的定价信息
DeepSeek 模型是开源的。DeepSeek 作为一个开源项目,允许开发者免费使用其模型进行研究和商业应用。这降低了使用先进人工智能技术的门槛,促进了技术的普及和创新。
虽然模型本身是免费的,但运行这些大模型需要大量的计算资源。根据您的需求和使用情况,可能需要考虑以下成本:
- 云服务费用:如果您选择在云平台上运行 DeepSeek 模型,例如 Google Colab、AWS 或 Azure,您需要支付相应的计算资源费用。
- 硬件成本:如果您选择在本地运行 DeepSeek 模型,您需要购买高性能的 GPU。
- 维护成本:如果您需要对 DeepSeek 模型进行定制和维护,您需要投入相应的人力和时间成本。
使用 Hugging Face Pipelines 的优缺点
👍 Pros
- 简单易用,快速上手
- 封装了底层细节,无需关注模型加载、预处理等步骤
- 支持多种 NLP 任务
- 可扩展性强,可以自定义模型和处理逻辑
👎 Cons
- 灵活性较低,难以定制
- 性能可能不如手动编写代码
- 对于复杂的 NLP 任务,可能需要进行额外的配置
DeepSeek 大模型的核心功能
DeepSeek R1
DeepSeek R1 拥有强大的文本生成能力,能够生成高质量、连贯且富有创意的文本。DeepSeek R1 的主要特性包括:
- 自然语言生成:可以用于生成各种类型的文本,例如文章、故事、新闻报道等。
- 文本摘要:可以将长篇文章自动提取关键信息,生成简洁的摘要。
- 对话生成:可以进行自然流畅的对话,适用于聊天机器人等应用。
它尤其擅长:
- 创造性写作:生成引人入胜的故事和诗歌。
- 生成代码:在各种流行编程语言中编写代码。
- 翻译文本:高质量的在不同语言之间翻译文本内容。
DeepSeek-Coder
DeepSeek-Coder 专门为代码生成任务设计,能够理解编程语言的结构和语义。
DeepSeek-Coder 的主要特性包括:
- 代码生成:可以根据自然语言描述自动生成代码片段。
- 代码补全:可以根据已有的代码自动补全后续代码。
- 代码翻译:可以将一种编程语言的代码翻译成另一种编程语言的代码。
它尤其擅长:
- 全自动代码补全:在你的项目中提供代码片段和建议,以加快编码速度。
- 调试支持:准确识别和修复代码中的错误。
- 创建测试用例:自动为生成的代码创建可靠的测试用例,保证质量。
DeepSeek 大模型的典型应用场景
内容创作
DeepSeek 可以用于自动生成各种类型的文本内容,如文章、故事、新闻报道等。这可以大大提高内容创作的效率,并降低成本。比如你可以通过使用 DeepSeek 来:
- 自动生成博客文章:告别写作瓶颈,快速产出高质量内容。
- 创作引人入胜的营销文案:用更少的精力,传递更有影响力的品牌信息。
- 自动撰写新闻稿件:实时生成快讯和新闻报道,分秒必争。
代码生成
DeepSeek-Coder 可以用于自动生成代码片段、代码补全和代码翻译等任务。这可以帮助开发者提高编码效率,并降低开发成本。比如你可以通过使用 DeepSeek 来:
- 快速生成代码:通过自然语言描述,DeepSeek-Coder 可以快速生成代码片段,无需手动编写。
- 提高代码质量:DeepSeek-Coder 可以根据已有的代码自动补全后续代码,并提供代码规范建议,从而提高代码质量。
- 实现跨平台开发:DeepSeek-Coder 可以将一种编程语言的代码翻译成另一种编程语言的代码,从而实现跨平台开发。
智能客服
DeepSeek 可以用于构建智能客服系统,自动回答用户的问题,并提供个性化的服务。这可以大大提高客户满意度,并降低客服成本。例如可以:
- 快速响应用户咨询:通过自动回答常见问题,缩短用户等待时间,提升服务效率。
- 提供个性化服务:根据用户历史行为和偏好,提供量身定制的解决方案。
- 7x24 小时全天候服务:保证任何时间都能获得帮助,不再错过任何客户。
常见问题解答
Pipelines 是否支持自定义模型?
是的,Pipelines 支持自定义模型。您可以将自己的模型加载到 Pipeline 中,并使用它进行推理。AutoClass 的使用,也支持灵活定制模型加载和处理过程。
Pipelines 是否支持 GPU 加速?
是的,Pipelines 支持 GPU 加速。您可以通过将模型和输入数据移动到 GPU 上,来提高推理速度。只需要在加载时添加 device = torch.device('cuda:0') 参数即可。
Pipelines 的输入数据有什么要求?
Pipelines 的输入数据通常是文本字符串。但是,对于某些任务,例如图像分类,Pipelines 也支持图像作为输入。
相关问题
Hugging Face Transformers 库还有哪些其他功能?
除了 Pipelines,Hugging Face Transformers 库还提供了许多其他功能,例如:
- 模型训练:Transformers 库提供了各种工具,帮助您训练自己的模型。
- 模型评估:Transformers 库提供了各种指标,帮助您评估模型的性能。
- 模型共享:Transformers 库提供了一个模型中心,您可以在这里共享自己的模型,并使用其他人的模型。
Transformers 库是一个功能强大的 NLP 工具包,可以帮助您完成各种 NLP 任务。有了 Hugging Face,你还可以:
- 与社区合作:与其他开发者合作,共同构建和改进模型。
- 参与开源项目:为 Transformers 库贡献代码,回馈社区。
- 学习最新技术:紧跟 NLP 领域的最新进展,不断提升自己的技能。
相关文章
