在人工智能领域,人物视频生成技术正以前所未有的速度发展。近年来,我们见证了AI在图像和视频创作方面的巨大进步,而Bytedance最新发布的OmniHuman项目,无疑是这一领域的一颗耀眼新星。OmniHuman能够利用单一图像和音频数据,生成令人惊叹的逼真人物视频,预示着内容创作方式的巨大变革。想象一下,仅仅提供一张照片和一段语音,AI就能让照片中的人物开口说话、唱歌,甚至表演,这不再是科幻小说中的情节,而是触手可及的现实。本文将深入探讨OmniHuman的技术原理、核心功能、潜在应用,以及它对未来内容创作生态可能产生的影响。OmniHuman的出现,为各行各业带来了无限可能。无论是教育、娱乐、营销,还是虚拟现实、人机交互,这项技术都将为我们提供更高效、更具创意的内容生成方式。然而,我们也需要正视这项技术可能带来的挑战,例如数据安全、版权保护、伦理道德等问题。只有在充分理解和合理利用的前提下,我们才能真正发挥OmniHuman的潜力,推动人工智能技术的可持续发展。让我们一起深入了解OmniHuman,探索AI技术赋能内容创作的未来。
OmniHuman视频生成技术核心要点
- OmniHuman是由Bytedance开发的AI人物视频生成技术。
- 它仅需单张图像和音频数据即可生成逼真的人物视频。
- 该技术支持多种视觉和音频风格,包括肖像、半身、全身等。
- OmniHuman能够处理各种宽高比的视频生成。
- 其核心优势在于能够生成高度逼真的面部表情和口型同步。
- 这项技术在教育、娱乐、营销等领域具有广泛的应用前景。
- 需关注其可能带来的数据安全、版权保护等伦理问题。
OmniHuman:重新定义AI人物视频生成
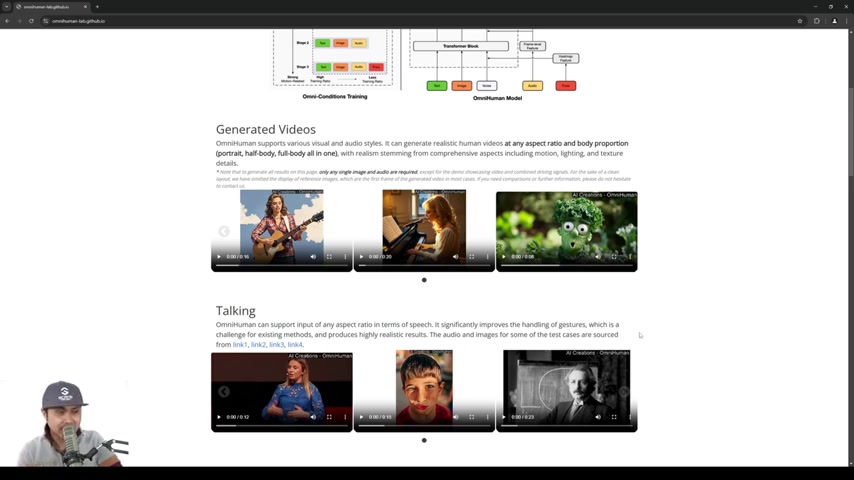
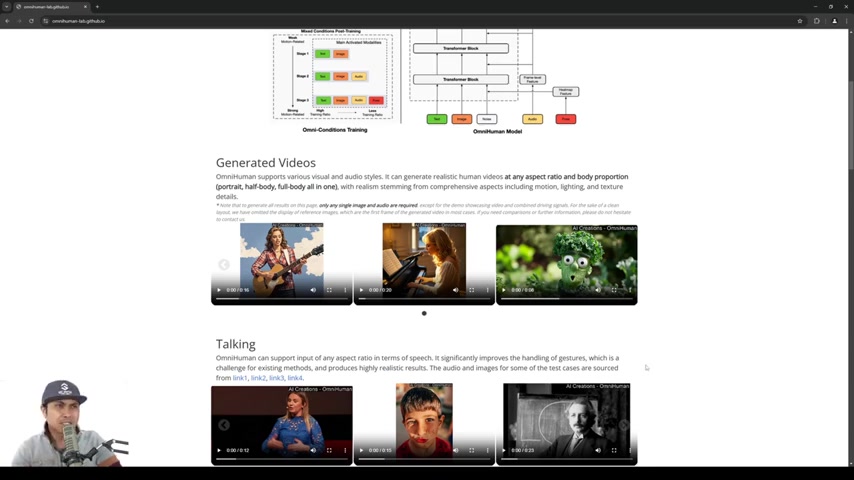
OmniHuman是什么?OmniHuman是一种由Bytedance开发的新型AI驱动的人物视频生成技术。它能够利用单一图像和音频作为输入,生成高度逼真的人物视频。该技术旨在克服现有方法的局限性,并显著提高生成视频的真实感和表现力。与传统的需要大量训练数据和复杂设置的方法不同,OmniHuman的设计理念是简单、高效和通用。这项技术可以支持各种视觉和音频风格,生成具有不同体型和比例的人物视频,例如,可以生成肖像、半身或者全身的人物形象。
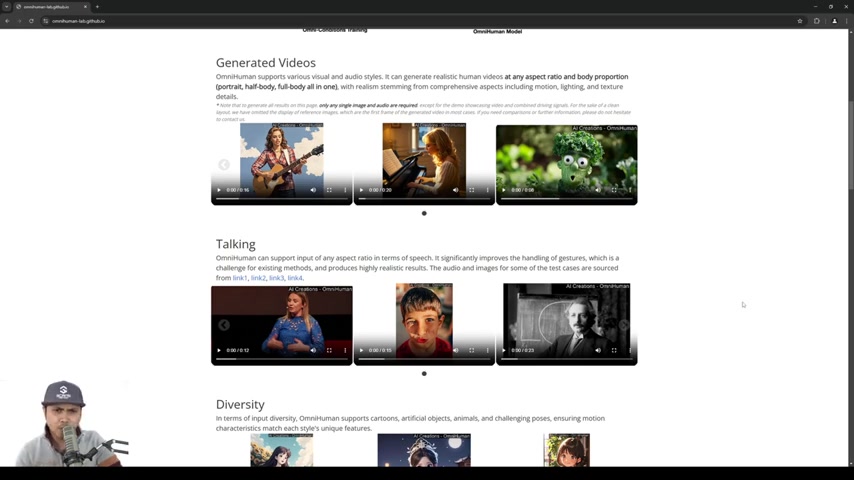
OmniHuman尤其擅长处理面部表情、口型同步和纹理细节,从而创造出令人信服的视频内容。它代表了AI在人物视频生成方面的一个重要里程碑,为内容创作者和各行各业提供了强大的工具。OmniHuman是Text to Video或Image to Video技术的新突破。
OmniHuman的技术特点
OmniHuman之所以能够在人物视频生成领域脱颖而出,得益于其独特的技术特点:
-
- 多模态输入:OmniHuman接受单张图像和音频作为输入,简化了视频生成的过程,降低了对大量训练数据的依赖。
- 高逼真度:该技术能够生成高度逼真的面部表情、口型同步和身体动作,使生成的人物视频更具表现力和感染力。
- 风格多样性:OmniHuman支持各种视觉和音频风格,可以生成不同类型的人物视频,满足不同应用场景的需求。
- 任意宽高比支持:该技术能够处理各种宽高比的视频生成,适应不同的平台和设备。
- 细节把控:OmniHuman在光照、纹理等细节方面表现出色,从而提高了生成视频的整体质量。
- 手势控制:能够支持输入任意比例的语音,显著改善手势的处理效果。
总之,OmniHuman凭借其多模态输入、高逼真度、风格多样性和细节把控等技术特点,为人物视频生成领域带来了全新的可能性。
OmniHuman:超越MetaHuman,引领AI视频新纪元
对比MetaHuman,OmniHuman的优势何在?目前,市面上已经存在一些人物视频生成技术,例如MetaHuman。那么,OmniHuman相比之下有哪些优势呢?
-
- 更强的易用性:MetaHuman需要用户具备专业的技术背景和操作经验,而OmniHuman则更加简单易用,即使是非专业人士也能轻松上手。
- 更高的生成效率:OmniHuman仅需单张图像和音频作为输入,大大缩短了视频生成的时间,提高了生成效率。
- 更低的硬件要求:MetaHuman对硬件配置要求较高,而OmniHuman则能够在较低配置的设备上运行,降低了使用门槛。
- 更强的适应性:OmniHuman对输入数据的适应性更强,能够处理不同质量的图像和音频,生成高质量的视频。
总而言之,OmniHuman在易用性、生成效率、硬件要求和适应性等方面都优于MetaHuman,更具市场竞争力。
OmniHuman:视频制作流程简易上手
使用OmniHuman生成人物视频的步骤使用OmniHuman生成人物视频非常简单,只需以下几个步骤:
- 准备输入数据:准备单张人物图像和一段音频,确保图像清晰、音频质量良好。
- 上传数据:将准备好的图像和音频上传到OmniHuman平台。
- 设置参数:根据需要,调整视频的视觉风格、宽高比等参数。
- 生成视频:点击生成按钮,等待OmniHuman自动生成人物视频。
- 预览和下载:预览生成的视频,如果满意,即可下载到本地设备。
整个过程简单、快捷,无需专业的视频编辑技能,即可轻松创作出逼真的人物视频。

OmniHuman:优势与挑战并存
优点
- 生成逼真的人物视频,具有高度的表现力和感染力。
- 仅需单张图像和音频作为输入,简化了视频生成的过程。
- 支持各种视觉和音频风格,满足不同应用场景的需求。
- 能够在较低配置的设备上运行,降低了使用门槛。
- 提供更高效、更具创意的内容生成方式。
缺点
- 可能存在数据安全和隐私泄露的风险。
- 可能引发版权纠纷和伦理道德问题。
- 生成视频的质量和逼真度可能受到输入数据质量的影响。
- 目前可能还无法完全控制生成视频的细节。
- 技术还在发展中,可能存在一些bug和不足。
OmniHuman常见问题解答
- OmniHuman需要哪些输入数据? OmniHuman只需要单张人物图像和一段音频作为输入数据。
- OmniHuman生成的视频逼真度如何? OmniHuman能够生成高度逼真的面部表情、口型同步和身体动作,使生成的人物视频更具表现力和感染力。
- OmniHuman支持哪些视觉和音频风格? OmniHuman支持各种视觉和音频风格,可以生成不同类型的人物视频,满足不同应用场景的需求。
- OmniHuman的硬件要求高吗? OmniHuman能够在较低配置的设备上运行,降低了使用门槛。
- OmniHuman可以应用于哪些领域? OmniHuman在教育、娱乐、营销、虚拟现实、人机交互等领域具有广泛的应用前景。
AI视频生成相关问题拓展
除了OmniHuman,还有哪些值得关注的AI视频生成技术?
近年来,AI视频生成技术取得了显著进展,涌现出许多令人印象深刻的项目。除了OmniHuman,以下是一些值得关注的技术:
- RunwayML Gen-2:这是一款强大的文本到视频生成工具,用户只需输入一段文字描述,即可生成高质量的视频片段。Gen-2在场景理解、物体建模和运动控制方面表现出色,能够创造出各种各样的视觉效果。
- Make-A-Video:由Meta AI开发的Make-A-Video同样是一款文本到视频生成工具。与Gen-2类似,它也能够根据文字描述生成视频,但更侧重于人物和动作的生成。Make-A-Video在面部表情、身体姿态和运动轨迹方面表现出色,能够创造出逼真的人物动画。
- Phenaki:Google Research推出的Phenaki是一款基于Transformer的视频生成模型。它能够根据一系列提示词生成连贯的视频,并且可以无限延长视频的长度。Phenaki在视频连贯性和长期依赖方面表现出色,能够创造出更具叙事性的视频内容。
- Imagen Video:同样由Google Research开发的Imagen Video是一款高质量的文本到视频生成模型。它能够根据文字描述生成逼真的视频,并且可以控制视频的风格和内容。Imagen Video在视频质量和可控性方面表现出色,能够创造出更具艺术性的视频作品。
- Synthesia:Synthesia是一款AI视频制作平台,用户可以通过简单的操作创建专业的视频内容。Synthesia提供了丰富的AI演员、模板和特效,用户可以轻松制作出各种类型的视频,例如营销视频、培训视频和教育视频等。
这些技术各有优势,共同推动了AI视频生成领域的发展。随着技术的不断进步,我们有理由相信,未来的视频创作将更加高效、便捷和富有创意。
| 技术名称 | 开发者 | 主要特点 | 擅长领域 |
|---|---|---|---|
| RunwayML Gen-2 | RunwayML | 文本到视频,场景理解、物体建模、运动控制 | 各种视觉效果 |
| Make-A-Video | Meta AI | 文本到视频,人物和动作生成,面部表情、身体姿态、运动轨迹 | 逼真的人物动画 |
| Phenaki | Google Research | 基于Transformer,一系列提示词生成连贯视频,可无限延长视频长度 | 视频连贯性和长期依赖 |
| Imagen Video | Google Research | 高质量文本到视频,逼真视频,控制视频风格和内容 | 视频质量和可控性 |
| Synthesia | Synthesia | AI视频制作平台,丰富的AI演员、模板和特效,简单操作创建专业视频内容 | 营销视频、培训视频、教育视频等 |
相关文章
