Perplexica核心要点
Perplexica是一款开源、隐私至上的AI搜索引擎。
它利用SearXNG进行安全的信息检索。
Perplexica允许用户本地化运行,保护个人数据。
可以与LM Studio等工具结合,实现本地AI模型驱动。
Perplexica提供强大的定制化搜索和会话式交互体验。
Perplexica概览
什么是Perplexica?
Perplexica是一个完全开源、以隐私为中心的AI搜索引擎,旨在成为商业化Perplexity AI的替代方案。它利用人工智能技术改进搜索结果并提供准确的信息,同时尊重用户隐私。Perplexica通过结合SearXNG(另一个开源的元搜索引擎)来确保搜索请求的匿名性,防止用户被追踪。与传统的搜索引擎不同,Perplexica允许用户完全掌控自己的搜索数据,无需担心隐私泄露的风险。此外,Perplexica还可以与LM Studio等工具集成,使用户能够在本地运行大型语言模型(LLM),实现更加个性化和安全的搜索体验。
Perplexica的独特优势
Perplexica与其他搜索引擎相比,具有以下显著优势:
- 开源透明:代码公开透明,用户可以审查和修改,确保安全可信。
- 隐私保护:基于SearXNG,不追踪用户数据,保护个人隐私。
- 本地化运行:支持本地运行LLM,数据完全掌控在用户手中。
- 定制化搜索:允许用户聚焦特定网站或上传本地文档进行搜索。
- 会话式交互:支持与AI模型进行对话式交互,深入探索信息。
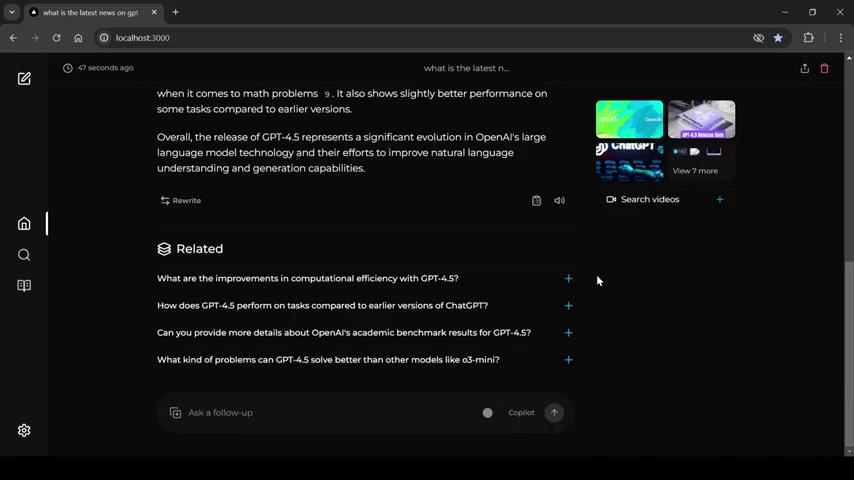
这使用户能够以清晰和有组织的方式探索和理解信息,并且减少了在不相关的网页中筛选信息所需要的时间和精力。通过这种简化的方法,Perplexica确保用户能够高效地找到他们所需要的答案,而不需要在不必要的资源中耗费时间。简单来说,Perplexica不仅仅是一个搜索引擎,更是一个安全、可控、个性化的AI信息助手。
Perplexica的技术架构
Perplexica的核心技术架构包括:
- SearXNG:负责收集和汇总来自多个搜索引擎的结果,确保搜索的全面性和匿名性。SearXNG的强大功能在于它能够从各种来源汇总结果,而不会跟踪用户或创建个人资料。这意味着用户可以获得更广泛的信息,而不会以牺牲隐私为代价。
- 大型语言模型(LLM):用于理解用户查询意图、提炼搜索结果、生成简洁摘要,并支持会话式交互。用户可以选择使用OpenAI、Grok等在线API,也可以选择在本地运行LLM,如通过LM Studio。
- 定制化功能:支持用户聚焦特定网站(如Reddit、YouTube)进行搜索,或上传本地文档进行分析。
- OpenAI兼容API:使得Perplexica可以轻松集成各种兼容OpenAI API的LLM,扩展其功能和应用场景。
Perplexica与LM Studio的完美结合
LM Studio简介
LM Studio是一款强大的工具,允许用户在本地运行各种开源大型语言模型(LLM)。它提供了一个简单易用的界面,方便用户下载、安装和配置各种LLM。LM Studio还内置了与OpenAI兼容的API,使得Perplexica可以轻松地调用本地运行的LLM进行搜索和信息处理。LM Studio的主要优势在于其易用性和对隐私的关注。通过在本地机器上运行LLM,用户可以避免将敏感数据发送到第三方服务器,从而保证了数据的安全性和隐私性。此外,LM Studio还支持各种模型格式和量化级别,允许用户根据自己的硬件配置和需求进行选择。
为何选择LM Studio?
使用LM Studio与Perplexica结合,可以带来以下显著优势:
- 隐私保护:所有数据处理都在本地进行,无需担心数据泄露。
- 定制化:选择适合自己需求的LLM,打造个性化的搜索体验。
- 离线可用:无需网络连接即可使用Perplexica,随时随地进行信息检索。
- 降低成本:无需支付API调用费用,节省开支。
- 更好的性能:本地运行LLM,响应速度更快,体验更流畅。
LM Studio是一个改变游戏规则的工具,它使广大用户能够利用先进的人工智能技术,而不需要大量的计算资源或专业知识。通过LM Studio,Perplexica用户可以直接在自己的设备上运行复杂的语言模型,从而保证了数据隐私,减少了对外部服务器的依赖,并可以定制他们的AI体验。
在LM Studio中选择合适的LLM
选择合适的LLM对于Perplexica的搜索体验至关重要。视频推荐了Qwen 3B Param V2 GGUF模型。这是一款由PinStack训练的轻量级、但功能强大的模型。它专门针对高级推理和工具使用进行了优化,而且具有较大的上下文窗口。在LM Studio中,用户可以根据自己的需求和硬件配置选择合适的LLM。一些常用的LLM包括:
- Llama 2:Meta发布的开源LLM,性能强大,应用广泛。
- Mistral:法国初创公司Mistral AI开发的LLM,性能出色,速度快。
- Qwen:阿里云发布的开源LLM,支持中文,擅长代码生成。
在选择LLM时,需要考虑以下因素:
- 模型大小:模型越大,性能越好,但需要更多的计算资源。
- 量化级别:量化级别越低,模型体积越小,但精度也会降低。
- 语言支持:选择支持所需语言的模型。
- 擅长领域:选择擅长所需任务的模型,如代码生成、文本摘要等。
Perplexica的安装与配置教程
准备工作
在开始安装Perplexica之前,需要确保满足以下条件:
- 安装Docker Desktop:Docker Desktop是运行Perplexica的必要条件,请确保已安装并运行。
- 安装Git:Git用于从GitHub克隆Perplexica的代码。
- 创建Perplexica项目文件夹:在计算机上创建一个用于存放Perplexica项目文件的文件夹。
- 下载并安装LM Studio: 确保已经下载并安装LM Studio.
- 下载本地模型: 需要从LM Studio中下载本地模型才能使用。
克隆Perplexica代码
打开命令行工具(如Windows的CMD或PowerShell),导航到之前创建的项目文件夹,然后运行以下命令:
git clone https://github.com/ltzCrazyKns/Perplexica.git
此命令会将Perplexica的代码从GitHub仓库克隆到本地。
配置Perplexica
克隆完成后,进入Perplexica文件夹,复制sample.config.toml文件并重命名为config.toml。使用文本编辑器打开config.toml文件,并根据需要进行配置。可以配置LLM提供商API密钥(如OpenAI API Key)或指向Ollama URL,但这些都可以在Perplexica图形界面进行修改。
启动Perplexica
在命令行工具中,导航到Perplexica项目文件夹,然后运行以下命令:
docker Compose up -d此命令会使用Docker Compose构建Perplexica镜像并启动容器。
配置LM Studio API
运行LM Studio并确保已加载本地语言模型。打开Perplexica并点击左下角的齿轮图标以访问设置。在“模型设置”下,将聊天模型提供商更改为“自定义_openai”。注意:此操作可能会导致UI界面跳动,如果没有显示API URL,只需要切换不同聊天模型即可重新显示。将Custom OpenAI Base URL更改为http://host.docker.internal:1234/v1。完成这些步骤之后,Perplexica将配置为使用LM Studio运行的本地AI模型,从而保证数据隐私和更快的响应时间。
修改LM Studio上下文长度
在LM Studio界面中点击服务器图标。点击推断选项卡,将上下文长度增加到至少12000。更高的值可以实现更好的记忆。单击重新加载应用更改。
使用Perplexica
打开浏览器,访问http://localhost:3000,即可开始使用Perplexica。在搜索框中输入查询内容,Perplexica将利用本地运行的LLM进行搜索,并返回结果。现在你可以体验完全由本地支持的人工智能搜索了!
Perplexica的优缺点分析
优点
- 开源透明,安全可信
- 保护用户隐私
- 支持本地化运行
- 定制化搜索功能
- 会话式交互体验
缺点
- 需要一定的技术基础
- 本地运行LLM受限于硬件配置
- 搜索结果质量依赖于LLM和SearXNG
- 安装配置过程相对复杂
- 对硬件资源要求较高
常见问题
Perplexica是否完全免费?
是的,Perplexica是完全开源的,可以免费使用。但如果需要调用在线API(如OpenAI API),则可能需要支付相关费用。
Perplexica是否支持中文?
是的,Perplexica支持中文搜索。但为了获得更好的中文搜索体验,建议选择支持中文的LLM。
Perplexica是否需要互联网连接?
如果使用在线API,则需要互联网连接。如果使用本地运行的LLM,则可以在离线状态下使用Perplexica。
Perplexica有哪些局限性?
Perplexica的搜索结果质量取决于所使用的LLM和SearXNG的配置。本地运行LLM的性能受限于硬件配置。
Docker占用的内存太多怎么办
可以修改Docker容器的资源限制,减少其占用的内存。具体方法请参考Docker文档。
相关问题
除了LM Studio,还有其他本地运行LLM的方案吗?
是的,除了LM Studio,还有其他一些流行的本地运行LLM的方案,例如:
- Ollama:Ollama是一个用于在本地设置和运行LLM的开源框架。它非常适合在Mac上运行,并提供简单的命令行界面,用于下载、运行和管理各种模型。https://ollama.com/
- 烛台:Candle是一个简约的Rust ML框架,重点在于简单性和性能。可以使用Candle在CPU和GPU上运行转换器模型,并支持各种模型架构。https://github.com/huggingface/candle
- GPT4All:GPT4All提供了一个全面的生态系统,用于在本地CPU上运行、训练和部署强大的语言模型。它包括一个模型库、GUI客户端和绑定,支持各种平台和编程语言。https://gpt4all.io/
选择哪个方案取决于您的具体需求和技术偏好。
如何提高Perplexica的搜索质量?
可以尝试以下方法来提高Perplexica的搜索质量:
- 选择合适的LLM:不同的LLM擅长不同的领域,选择适合自己需求的LLM。
- 优化SearXNG配置:配置SearXNG,选择合适的搜索引擎和参数。
- 调整Perplexica参数:调整Perplexica的参数,如上下文长度、温度等。
- 使用高质量的嵌入模型:用于对搜索结果进行语义编码,提高相关性判断的准确性。
- 训练自己的LLM:可以根据自己的需求,训练一个定制化的LLM。
通过以上方法,可以不断优化Perplexica的搜索质量,使其更好地满足个人需求。
相关文章
