在人工智能不断发展的领域中,出现了一种新的模型,重新定义了视觉-语言理解的边界。Seed1.5-VL,由字节跳动Seed开发,代表了AI在处理和推理多样视觉与文本输入能力上的重大飞跃。这一创新AI在多个理解基准测试中创造了新的记录,超越了当前领先的系统在软件控制和类代理任务中的表现。其效率和强大的推理能力使其成为该领域值得关注的进步。
关键点
- Seed1.5-VL是一种新的视觉-语言AI,在众多理解基准测试中创造了破纪录的表现。
- 该模型利用视觉编码器和混合专家(MoE)架构进行高效处理。
- 它在多样视觉任务中表现出强大的推理能力,特别是在以代理为中心的场景和多模态推理中。
- 该AI在理解和解释不同分辨率和宽高比的图像和视频方面展示了令人印象深刻的能力。
- 训练后阶段包括监督微调和强化学习,以增强问题解决和推理能力。
理解Seed1.5-VL
什么是Seed1.5-VL?
Seed1.5-VL是一种视觉-语言基础模型,旨在推进通用多模态理解和推理。作为一种尖端AI,Seed1.5-VL被设计为具有广泛的适用性,使其能够处理需要综合视觉和语言数据的各种任务。其核心设计促进了对图像和视频的细致理解,结合文本上下文,使其能够执行从简单对象识别到复杂场景和事件推理的任务。这是通过结合专门的视觉编码器和混合专家(MoE)架构实现的,优化了性能和效率。视觉编码器允许模型从输入图像和视频中提取相关视觉特征,而MoE架构确保仅激活神经网络中最相关的部分进行任何给定任务,从而减少计算负载并提高处理速度。这种准确性和效率之间的平衡对于在资源可能有限且响应时间至关重要的现实应用中部署AI解决方案至关重要。简而言之,Seed1.5-VL代表了AI领域的关键进步,结合了最先进的技术,实现了前所未有的多模态理解和推理水平,为未来AI开发和应用程序设定了新标准。

Seed1.5-VL的架构
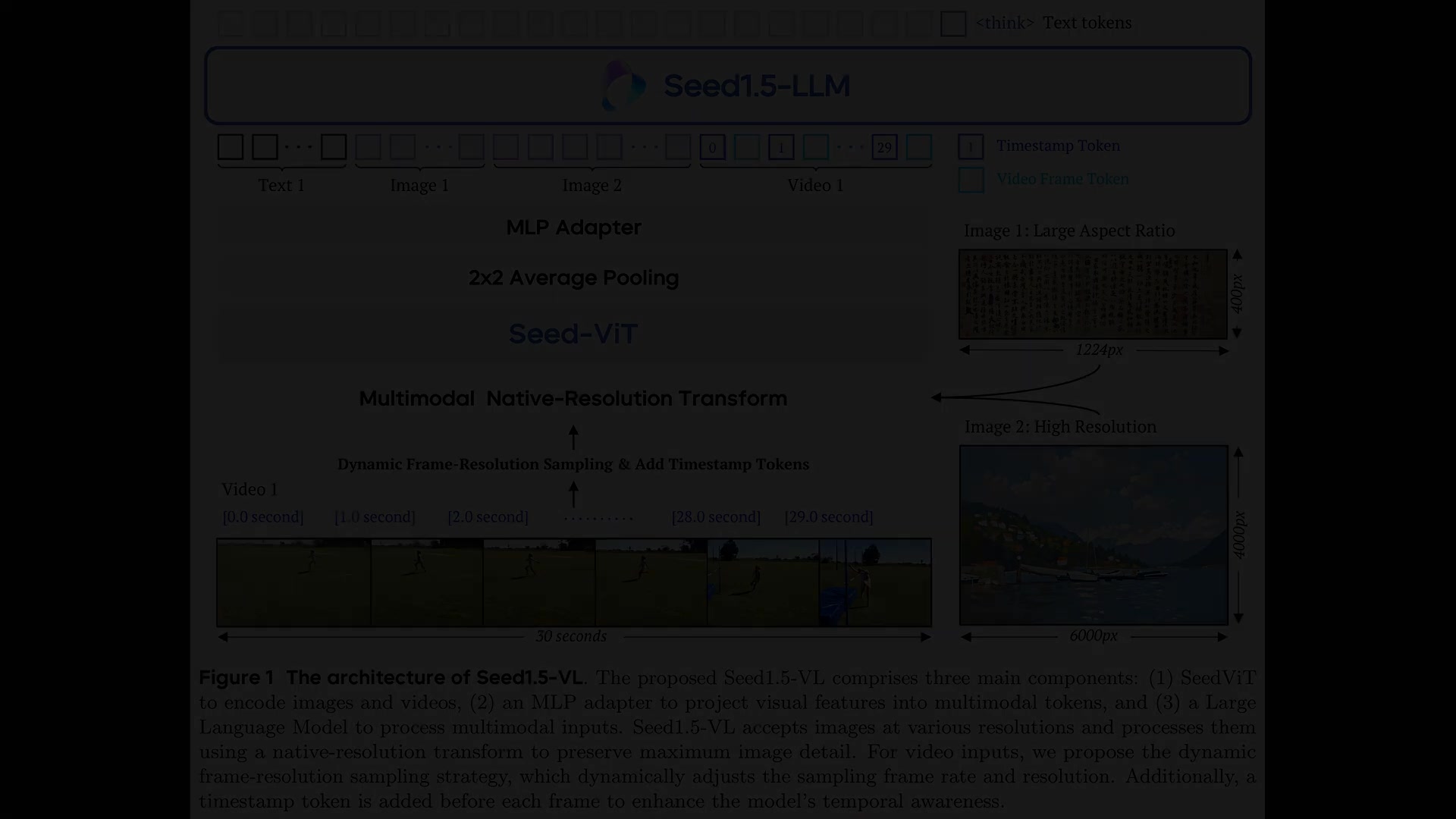
Seed1.5-VL的架构设计使其能够有效处理和整合视觉与文本信息。其核心使用视觉编码器,特别是Seed视觉Transformer(Seed-ViT),从图像和视频中提取特征。这一组件对于捕捉视觉数据中的空间和时间细节至关重要。Seed-ViT以其原生分辨率处理输入,有助于保留在调整大小时可能丢失的图像细节。此外,设计包括一个MLP适配器,将视觉特征投影到多模态标记中,使其能够与AI的大型语言模型(LLM)方面无缝对接。该适配器确保视觉数据被适当格式化,以便LLM能够理解并对其进行推理。一个独特的元素是带有时间戳标记的动态帧分辨率采样,使其能够调整视频的帧率并将时间意识整合到其分析中。最后,LLM使用混合专家处理所有输入。混合专家的使用意味着仅激活网络的特定部分进行每个任务,使其在处理多样多模态数据时更加高效和精确。整个架构设计用于最佳多模态处理,确保其能够有效处理广泛的复杂推理任务。
训练数据和方法
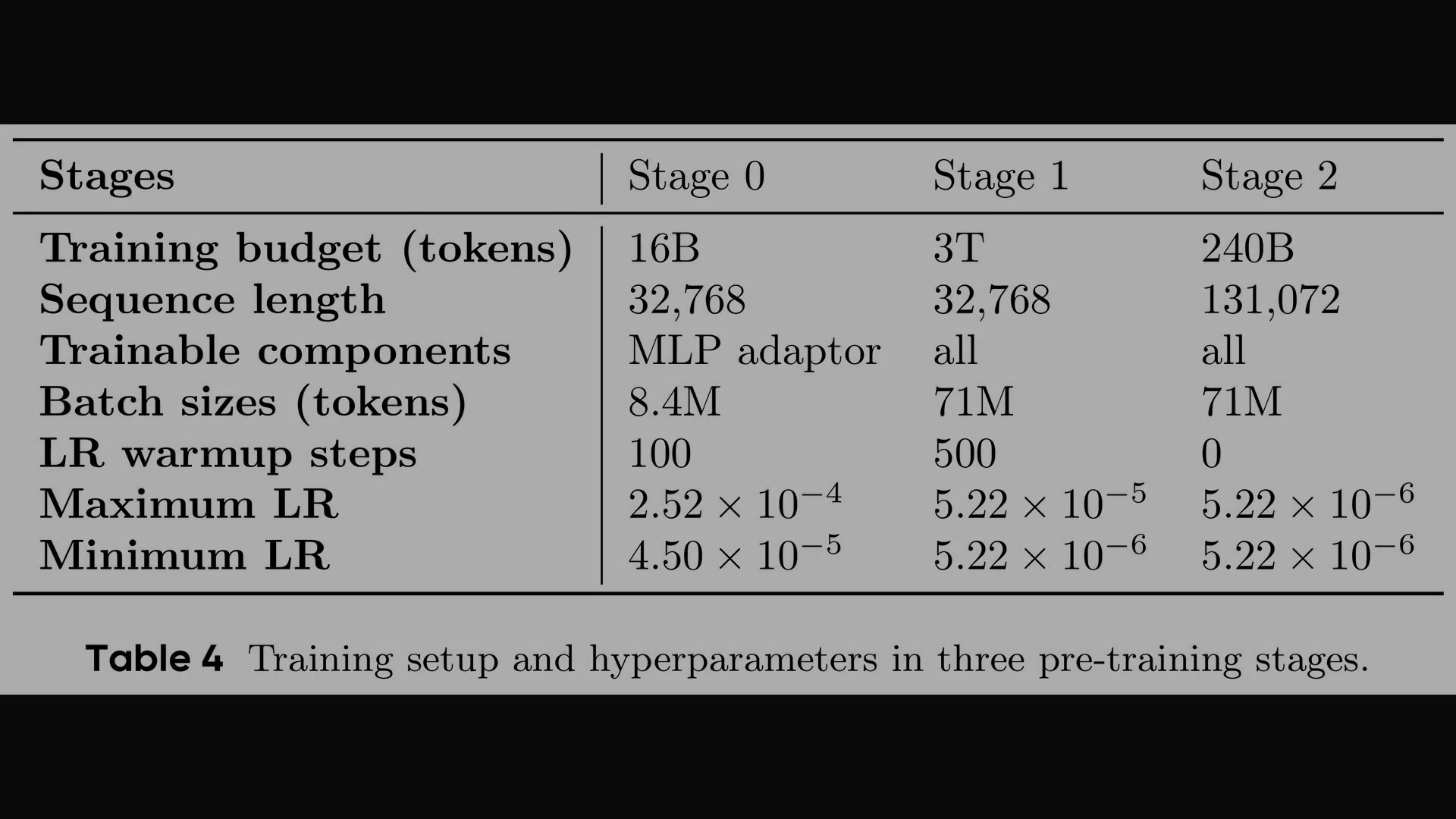
Seed1.5-VL的性能在很大程度上依赖于其训练数据和方法,这些数据和方法经过精心设计,以增强其多模态理解和推理能力。AI在包括大量合成数据的多样化数据集上进行了广泛训练。这些合成数据特别适用于光学字符识别(OCR)和视觉接地等任务,帮助其识别图像中的文本并建立单词与视觉内容之间的联系。这些广泛的训练数据随后用于三个预训练阶段,每个阶段都经过精心校准,调整学习率和可训练组件。最初,仅训练MLP适配器,而后期阶段涉及对所有组件进行微调,并精确调整学习率。训练期间的精心校准确保了对模型的最佳优化,提高了其在不同任务中的泛化和表现能力。训练设置包括调整序列长度和使用非常大的批量大小,所有这些对于实现高性能至关重要。作为关键的最后一步,Seed1.5-VL经过详细的训练后过程,结合了监督微调和强化学习,优化了其问题解决和推理能力。它使用硬提示来推动模型的边界,并确保其能够处理具有挑战性的输入和输出。通过将强化学习集中在最终生成的输出上,它避免了对详细思维链推理的监督,这一决定使其能够开发出更细致的解决方案。
Seed1.5-VL的基准测试
性能和能力
基准测试是评估Seed1.5-VL能力并将其与其他领先AI模型进行比较的重要步骤。在其对多模态推理、通用视觉问答和文档理解等多样化能力的评估中,这一评估过程证实了其实现最先进结果的能力。例如,在文档和图表理解中,它在光学字符识别(OCR)中获得了非常高的分数,显示出在解释图像中的文本方面的高度熟练度。它还在处理图形用户界面(GUI)方面展示了竞争优势,有效地接地并使用界面中的视觉元素来执行任务。这一基准测试突出了AI不仅能够理解视觉和文本元素,而且能够交互地使用它们,以显著的效率执行以代理为中心的任务。所使用的基准测试证实了它在理解和实际应用方面都表现出色,使其成为各种现实场景中的宝贵工具。

Seed1.5-VL的用例
软件和类代理任务
Seed1.5-VL在软件控制和类代理任务中表现出色,这些任务需要高度的视觉和语言理解。其有效地与图形用户界面(GUI)交互并从文本输入中解释指令的能力,使其在自动化软件操作和管理数字环境中非常有价值。示例包括自动导航网页、从在线来源提取数据,甚至以编程方式操作移动应用程序。其应用在客户服务中也很有帮助,可以用于指导用户通过复杂的软件界面。其在以代理为中心的任务中的能力使其能够作为虚拟助手,不仅理解请求,还通过与软件或数字平台交互来执行它们。在软件测试和质量保证领域,Seed1.5-VL可以自动化测试,通过分析界面响应识别错误,并提供详细报告,显著减少手动测试工作并提高软件质量。AI在视觉和语言处理方面的综合优势使其成为应对软件相关挑战的多功能工具,使其能够弥合人类意图与机器执行之间的差距,为AI如何用于优化软件交互设定了先例。
Seed1.5-VL的优缺点
👍 优点
- 卓越性能:在多个基准测试中创造了新记录。
- 高效率:使用混合专家(MoE)进行针对性处理。
- 强大推理:能够处理复杂的视觉任务和多模态交互。
- 广泛适用性:适用于多种应用,包括软件控制和自动化代理任务。
👎 缺点
- 高计算需求:训练和推理可能需要大量资源。
- 数据依赖性:性能依赖于训练数据的质量和多样性。
- 合成数据偏差:使用合成生成的数据可能会引入偏差。
- 复杂性:先进的架构可能难以实施和维护。
常见问题解答
Seed1.5-VL使用什么样的数据进行训练?
Seed1.5-VL使用多种数据进行训练,包括合成生成的数据。这包括用多边形突出显示文本的图像、带有相关问题的合成图表和扭曲的文档,以及真实世界的数据。
Seed1.5-VL的核心组件是什么?
核心组件包括SeedViT,这是一种从图像和视频中提取视觉特征的视觉编码器。还包括一个MLP适配器,将视觉特征投影到多模态标记中,以及一个处理多模态输入的大型语言模型。
什么是混合专家(MoE)方法?
混合专家(MoE)方法允许仅激活网络的特定部分进行每个任务,使其更加高效,并使其能够以更高的精度处理多模态数据。
该模型在哪些以代理为中心的任务中表现出色?
该模型在涉及与图形用户界面交互的任务中表现出色,例如GUI接地和浏览器使用。它被设计为允许AI作为代理与界面交互并实现实际目标。
相关问题
Seed1.5-VL与其他视觉-语言模型相比如何?
Seed1.5-VL通过结合视觉Transformer和混合专家(MoE),在许多基准测试中实现了最先进的性能,这使其在处理多模态推理挑战(如视觉谜题)时特别有效。它还在理解和实际应用方面取得了令人印象深刻的结果,使其成为各种现实场景中的宝贵工具。这代表了与其他模型相比在方法和整体性能上的重大进步。
什么是视觉接地,为什么它很重要?
视觉接地是将单词连接到相应图像区域的能力,使模型能够理解和推理不同类型的多模态信息。它提供了一种使语言更接地于实际所见的方式,使其在需要语言指导以确定图像中正确区域的实际应用(如人机交互和图像编辑)中至关重要。
相关文章
