在人工智能领域,视觉和语言的融合一直是研究的热点。Seed1.5-VL,作为一种新型的视觉语言AI模型,正引领着这一领域的创新。该模型不仅在多项基准测试中取得了令人瞩目的成绩,还在实际应用中展现了强大的多模态理解和推理能力。本文将深入解读Seed1.5-VL的技术报告,剖析其架构设计、训练方法和性能表现,并探讨其在未来的应用前景。
Seed1.5-VL的出现,标志着AI在理解和处理复杂视觉信息方面迈出了重要一步,为软件控制、智能代理等任务提供了强大的技术支持。多模态AI是当前人工智能发展的重要方向,它致力于让AI能够像人类一样,同时理解和处理来自不同感官的信息,例如视觉、听觉和语言。Seed1.5-VL正是在这一领域的一次重要尝试,通过融合视觉和语言信息,实现了更全面的环境感知和更智能的决策能力。
本文旨在为对AI技术感兴趣的读者提供一个全面而深入的了解,帮助大家把握多模态AI的发展趋势,并洞察其在未来的应用潜力。通过本文的阅读,您将了解到Seed1.5-VL的核心技术、关键优势以及在实际应用中的潜力。无论您是AI领域的专业人士,还是对AI技术感兴趣的爱好者,相信本文都能为您带来有价值的思考和启发。让我们一起深入探索Seed1.5-VL,见证多模态AI的未来发展。
Seed1.5-VL:多模态AI的关键要点
- Seed1.5-VL在38项理解基准测试中创下新纪录,证明了其卓越的多模态理解能力。
- 该模型在软件控制和智能代理等任务中表现优异,超越了其他领先的AI模型。
- Seed1.5-VL采用高效的AI模型,在各种视觉任务中展现出强大的推理能力。
- 该模型的设计目标是实现广泛的多模态理解和推理,利用视觉编码器和混合专家模型(MoE)。
- Seed1.5-VL通过动态帧率分辨率采样和时间戳标记,能够有效处理视频输入。
- 该模型的架构旨在最大程度地保留图像细节,从而提升视觉信息的处理质量。
Seed1.5-VL技术报告:全面解析
Seed1.5-VL:新型视觉语言AI模型简介
Seed1.5-VL是一种旨在实现通用多模态理解和推理的视觉语言基础模型。该模型由字节跳动Seed团队开发,其技术报告在Hugging Face的趋势列表中迅速攀升,引发了广泛关注。

Seed1.5-VL模型的核心在于其能够有效地处理和理解来自不同来源的信息,包括图像、视频和文本。这使得它能够在各种复杂的任务中表现出色,例如:
- 视觉问答:根据图像内容回答问题。
- 图像描述:生成图像的自然语言描述。
- 视觉推理:对图像中的对象、关系和场景进行推理。
- 智能代理:在虚拟环境中执行任务。
为了实现这些功能,Seed1.5-VL采用了混合专家模型(MoE),一种能够根据输入动态选择性激活网络部分的高效架构。这种架构使得模型能够在保持高性能的同时,显著降低计算成本。
Seed1.5-VL的成功,归功于其创新的设计理念和精细的训练方法。该模型不仅在技术上有所突破,还在应用层面展现了广阔的前景。在接下来的内容中,我们将深入探讨Seed1.5-VL的各项关键技术,并分析其在实际应用中的潜力。
Seed1.5-VL的架构设计:视觉编码器与混合专家模型
Seed1.5-VL的架构设计是其成功的关键因素之一。该模型采用了视觉编码器和混合专家模型(MoE)相结合的方式,实现了对多模态信息的有效处理。

视觉编码器的作用是将图像和视频转换为模型可以理解的特征向量,而混合专家模型则负责对这些特征向量进行推理和决策。
视觉编码器:提取视觉特征
Seed1.5-VL的视觉编码器采用了Seed-ViT,一种专门为处理高分辨率图像和视频而设计的视觉Transformer模型。Seed-ViT能够在保留图像细节的同时,有效地提取视觉特征。为了处理不同尺寸和宽高比的图像,Seed-ViT还采用了多模态原生分辨率变换技术,确保模型能够以最佳分辨率处理各种视觉输入。
混合专家模型(MoE):提升模型容量与效率
Seed1.5-VL采用了混合专家模型(MoE),这种架构能够显著提升模型的容量,同时降低计算成本。在MoE架构中,模型包含多个“专家”子网络,每个专家网络负责处理特定类型的输入。通过一个门控机制,模型能够根据输入动态地选择激活哪些专家网络,从而实现高效的计算。
具体来说,Seed1.5-VL的MoE模型包含多个前馈网络,每个前馈网络都可以被视为一个“专家”。门控机制根据输入特征,为每个专家网络分配一个权重,然后将所有专家网络的输出加权求和,得到最终的输出。这种方式使得模型能够根据输入的不同,动态地调整其结构,从而更好地适应不同的任务。
MoE架构的优势在于:
- 更高的模型容量:通过增加专家网络的数量,可以显著提升模型的容量,使其能够学习更复杂的模式。
- 更低的计算成本:每次只激活部分专家网络,可以显著降低计算成本,提高模型的训练和推理效率。
通过将视觉编码器和混合专家模型相结合,Seed1.5-VL实现了对多模态信息的高效处理和理解,为其在各种任务中取得优异表现奠定了基础。
Seed1.5-VL的训练策略:动态帧率分辨率采样与时间戳标记
Seed1.5-VL的训练策略是其成功的另一个关键因素。为了有效地处理视频输入,该模型采用了动态帧率分辨率采样和时间戳标记技术。
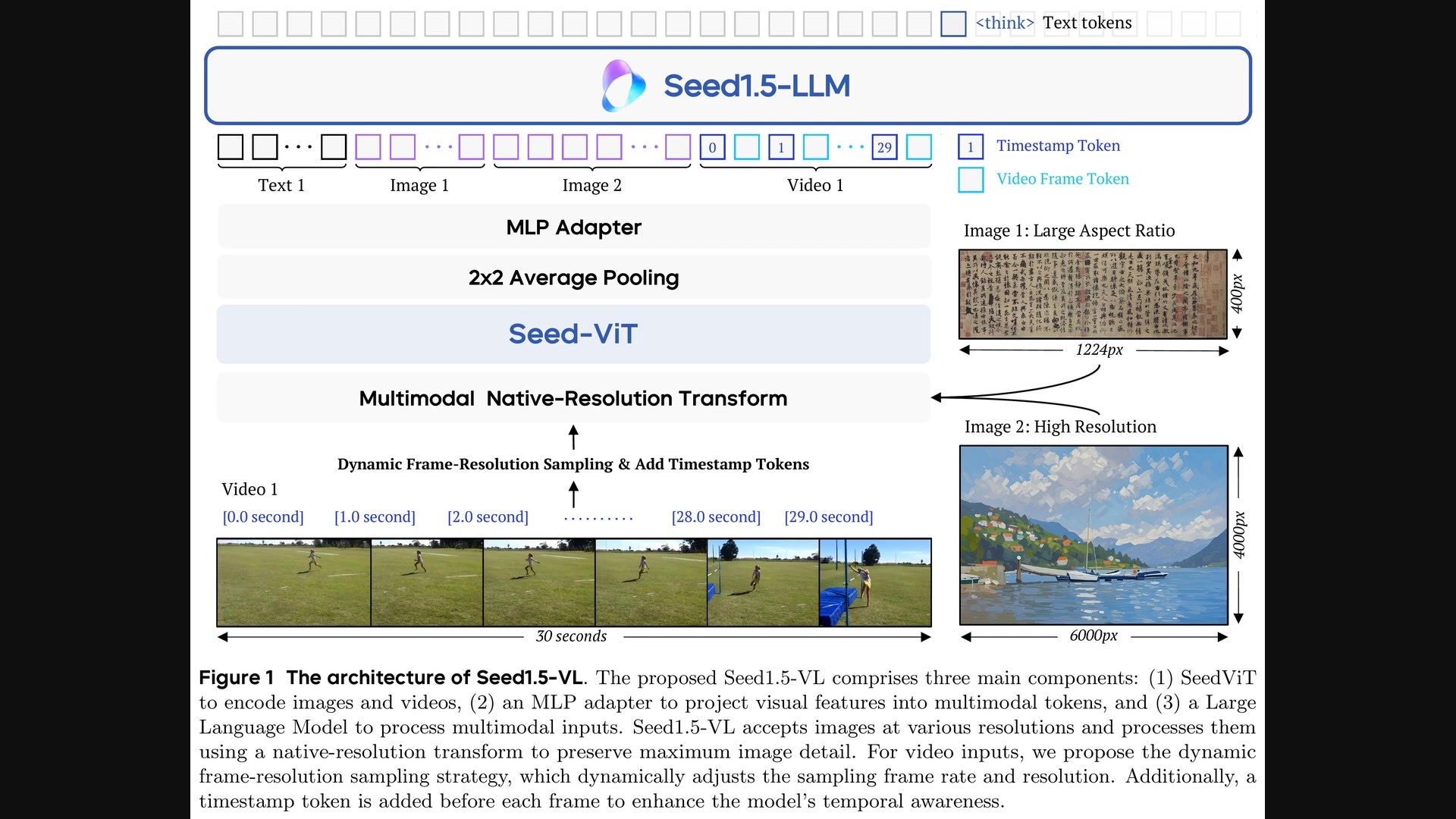
这些技术能够帮助模型更好地理解视频内容,并从中提取有用的信息。
动态帧率分辨率采样
视频的帧率是指每秒钟播放的图像数量。高帧率的视频能够提供更流畅的视觉体验,但同时也需要更高的计算资源。为了在保持视频质量的同时,降低计算成本,Seed1.5-VL采用了动态帧率分辨率采样技术。该技术能够根据视频内容的复杂程度,动态地调整帧率和分辨率。对于内容变化缓慢的视频片段,模型会降低帧率和分辨率,以减少计算量。而对于内容变化快速的视频片段,模型则会提高帧率和分辨率,以捕捉更多的细节。
时间戳标记
为了让模型更好地理解视频中的时间信息,Seed1.5-VL采用了时间戳标记技术。该技术将时间信息嵌入到视频帧中,使得模型能够感知到不同帧之间的时间关系。具体来说,模型会将每个视频帧对应的时间戳转换为一个特殊的标记(token),然后将这个标记添加到该帧的特征向量中。通过这种方式,模型就能够了解到每个帧在视频中的位置,以及不同帧之间的时间间隔。
动态帧率分辨率采样和时间戳标记技术的结合,使得Seed1.5-VL能够有效地处理视频输入,并从中提取有用的信息。这为模型在视频理解和推理任务中取得优异表现提供了有力的支持。
Seed1.5-VL的性能表现:基准测试与实际应用
Seed1.5-VL在各项基准测试中取得了令人瞩目的成绩,证明了其卓越的多模态理解和推理能力。该模型在38项理解基准测试中创下新纪录,并在软件控制和智能代理等任务中超越了其他领先的AI模型。
基准测试
Seed1.5-VL在以下基准测试中表现出色:
- MMMU:测试模型的多模态推理能力。
- MathVista:测试模型的视觉数学能力。
- RealWorldQA:测试模型在现实世界场景中的问答能力。
- DocVQA:测试模型对文档图像的理解和问答能力。
实际应用
Seed1.5-VL在实际应用中也展现了广阔的前景。该模型可以应用于以下领域:
- 智能客服:帮助客服人员理解用户的问题,并提供更准确的答案。
- 自动驾驶:帮助车辆理解周围环境,并做出更安全的决策。
- 智能家居:帮助家居设备理解用户的意图,并提供更便捷的服务。
Seed1.5-VL的卓越性能,使其在各个领域都具有广泛的应用前景。随着技术的不断发展,我们有理由相信,Seed1.5-VL将在未来的人工智能领域发挥越来越重要的作用。
OCR和视觉定位:Seed1.5-VL如何理解图像中的文本
Seed1.5-VL在OCR任务中的应用
在数字化时代,从图像中提取文本信息变得越来越重要。光学字符识别(OCR)技术可以将图像中的文本转换为机器可读的格式,从而方便我们进行搜索、编辑和分析。
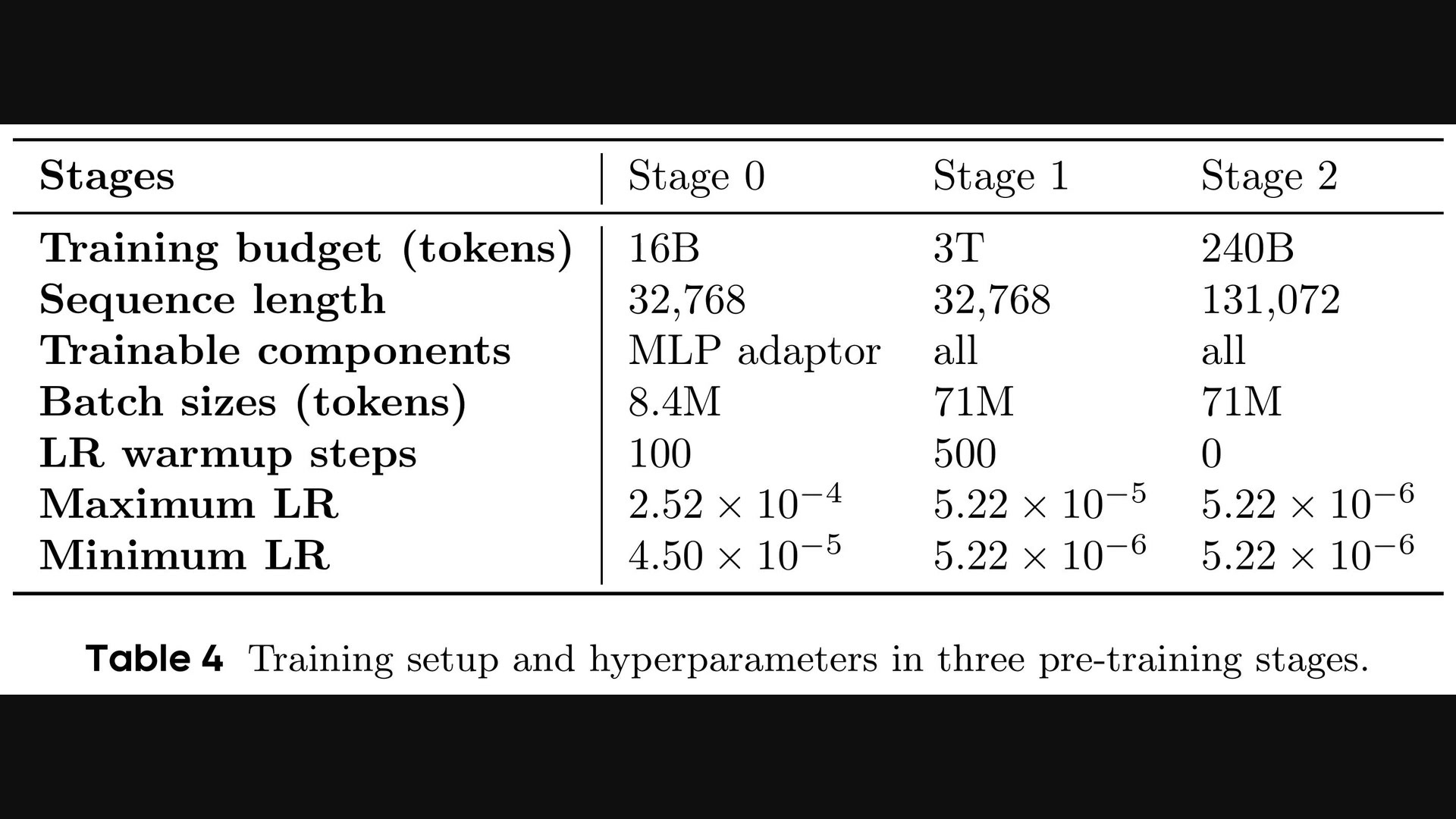
Seed1.5-VL在OCR任务中展现出了强大的能力,这得益于其先进的架构设计和训练方法。Seed1.5-VL采用了合成数据进行训练,这是一种通过计算机生成模拟图像和文本的技术。合成数据可以帮助模型更好地理解各种字体、颜色和背景下的文本,从而提高OCR的准确率。具体来说,研究人员使用了SynthDog来生成这些数据。
Seed1.5-VL不仅能够识别图像中的文本,还能够定位文本在图像中的位置。这种视觉定位能力对于理解图像内容至关重要。例如,在处理包含图表的图像时,模型需要能够定位图表的标题、坐标轴标签和数据点,才能正确地理解图表所表达的信息。
Seed1.5-VL的OCR和视觉定位能力,使其能够有效地处理各种包含文本的图像,例如:
- 扫描文档:将扫描的纸质文档转换为可编辑的电子文档。
- 路牌识别:在自动驾驶系统中,识别路牌上的文字信息。
- 产品标签识别:在电商领域,识别产品标签上的文字信息。
随着OCR和视觉定位技术的不断发展,Seed1.5-VL将在未来的各个领域发挥越来越重要的作用。
Seed1.5-VL:如何在实际项目中应用
步骤一:环境搭建与依赖安装
要开始使用Seed1.5-VL,首先需要搭建一个合适的开发环境。这通常涉及到安装必要的软件库和配置硬件资源。以下是一些建议的步骤:
- 安装Python:Seed1.5-VL通常基于Python开发,因此需要确保安装了Python 3.7或更高版本。
- 安装PyTorch:Seed1.5-VL依赖于PyTorch深度学习框架,需要根据您的操作系统和硬件配置,选择合适的PyTorch版本进行安装。访问PyTorch官网(https://pytorch.org/)可以找到详细的安装指南。
- 安装Hugging Face Transformers库:Transformers库提供了许多预训练模型和工具,可以方便地使用Seed1.5-VL。您可以使用pip命令安装该库:
pip install transformers - 安装其他依赖库:根据Seed1.5-VL的具体应用场景,可能还需要安装其他依赖库,例如用于图像处理的PIL库、用于数据处理的pandas库等。
在安装依赖库时,建议使用虚拟环境,以避免不同项目之间的依赖冲突。您可以使用venv或conda等工具创建虚拟环境。
步骤二:模型加载与配置
完成环境搭建后,就可以开始加载Seed1.5-VL模型了。您可以通过Hugging Face Hub下载预训练模型,或者使用自己训练的模型。以下是一些常用的模型加载方法:
- 从Hugging Face Hub加载模型:使用Transformers库可以方便地从Hugging Face Hub加载预训练模型。
- 加载本地模型:如果您有自己训练的模型,可以使用PyTorch的
torch.load()函数加载模型。 - 模型配置:根据您的应用场景,可能需要对模型进行一些配置,例如调整模型的大小、修改模型的参数等。您可以使用Transformers库提供的
AutoConfig类加载模型的配置信息,并进行修改。
在加载模型时,需要注意以下几点:
- 模型版本:确保加载的模型版本与您的代码兼容。
- 硬件资源:确保您的硬件资源能够满足模型的需求。如果您的GPU显存不足,可以尝试使用更小的模型或减少batch size。
步骤三:数据预处理
Seed1.5-VL模型需要接收特定格式的输入数据。因此,在使用模型之前,需要对输入数据进行预处理。以下是一些常用的数据预处理方法:
- 文本数据预处理:对于文本数据,需要进行分词、去除停用词、转换为模型可以理解的token等操作。您可以使用Transformers库提供的tokenizer工具进行文本数据预处理。
- 图像数据预处理:对于图像数据,需要进行缩放、裁剪、归一化等操作。您可以使用PIL库或torchvision库进行图像数据预处理。
- 视频数据预处理:对于视频数据,需要进行帧提取、帧率调整、图像数据预处理等操作。您可以使用OpenCV库进行视频数据预处理。
在进行数据预处理时,需要注意以下几点:
- 数据格式:确保预处理后的数据格式与模型的要求一致。
- 数据类型:确保预处理后的数据类型与模型的要求一致。
- 数据范围:确保预处理后的数据范围与模型的要求一致。
步骤四:模型推理与结果解析
完成数据预处理后,就可以将数据输入到Seed1.5-VL模型中进行推理了。以下是一些常用的模型推理方法:
- 使用Transformers库进行推理:Transformers库提供了方便的
pipeline工具,可以简化模型推理的过程。 - 使用PyTorch进行推理:如果您需要更灵活的控制,可以使用PyTorch的
model.forward()函数进行推理。 - 结果解析:模型推理后会输出一些结果,您需要根据您的应用场景,对这些结果进行解析。例如,对于视觉问答任务,模型会输出一个答案;对于图像描述任务,模型会输出一段描述文本。
在进行模型推理时,需要注意以下几点:
- 输入数据:确保输入数据与模型的要求一致。
- 推理模式:确保模型处于推理模式,而不是训练模式。
- 硬件资源:确保您的硬件资源能够满足模型的需求。
Seed1.5-VL:不同使用场景的定价策略
Seed1.5-VL的定价模式分析
目前,Seed1.5-VL的技术报告主要关注模型的技术细节和性能评估。官方尚未公布详细的定价信息。然而,考虑到其性质,可以推测其定价模式可能包括以下几种:
- 开源免费使用:研究团队可能选择开源Seed1.5-VL模型,允许研究人员和开发者免费使用。但可能对商业用途进行限制。
- API调用次数:Seed1.5-VL可能以API形式提供服务,根据API调用次数进行收费。这种模式适合于需要少量使用模型,或者需要快速集成的场景。
- 按计算资源计费:如果您需要更大的计算资源或更长的运行时间,可能需要购买更高级别的套餐。这种模式适合于需要高性能和大规模部署的场景。
- 定制化解决方案:对于有特殊需求的企业,可以提供定制化的解决方案,例如模型定制、私有部署等。这种模式通常价格较高,但能够满足企业的个性化需求。
考虑到多模态AI模型的复杂性,合理的定价策略对于Seed1.5-VL的推广和应用至关重要。我们期待官方能够尽快公布详细的定价信息,以便用户更好地评估和选择。
Seed1.5-VL:优缺点分析
优点
- 卓越的多模态理解能力,能够在各种基准测试中创下新纪录。
- 在软件控制和智能代理等任务中表现优异,超越了其他领先的AI模型。
- 采用高效的AI模型,在各种视觉任务中展现出强大的推理能力。
- 采用混合专家模型(MoE)架构,能够在保持高性能的同时,显著降低计算成本。
- 通过动态帧率分辨率采样和时间戳标记,能够有效处理视频输入。
缺点
- 模型结构较为复杂,需要一定的技术门槛才能理解和使用。
- 需要大量的计算资源进行训练和推理。
- 目前主要应用于研究领域,在实际应用中的经验还比较有限。
- 对于某些特定类型的任务,可能需要进行定制化训练才能达到最佳效果。
相关文章
